Text selection option = Configured to perform a columnar selection? #974
-
|
When using the text selection tool to capture multiple lines of text, the beginning-point of the text capture is where the mouse-down event occurred and the end-point is the location on the last line where the mouse-up event occurred (similar to this italicized text). The extracted text includes all text from the beginning-point to the end-point, concatenating the text from each line to the first line, thus creating one very long string - similar to the way that same process works in a simple editor like notepad. However, I'm wanting to extract columnar text, rather than full-line text, similar to the way VSCode does with either a keyboard combination (ALT-Shift-Mouse-down, mouse-drag) or a separate user setting (Toggle Column Selection Mode). Using that setting allows me to extract the text from multiple lines but capture only columns 3 through 5 of a 7 column display. How do I configure ngx-extended-pdf-viewer to provide the same capability? |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 1 reply
-
|
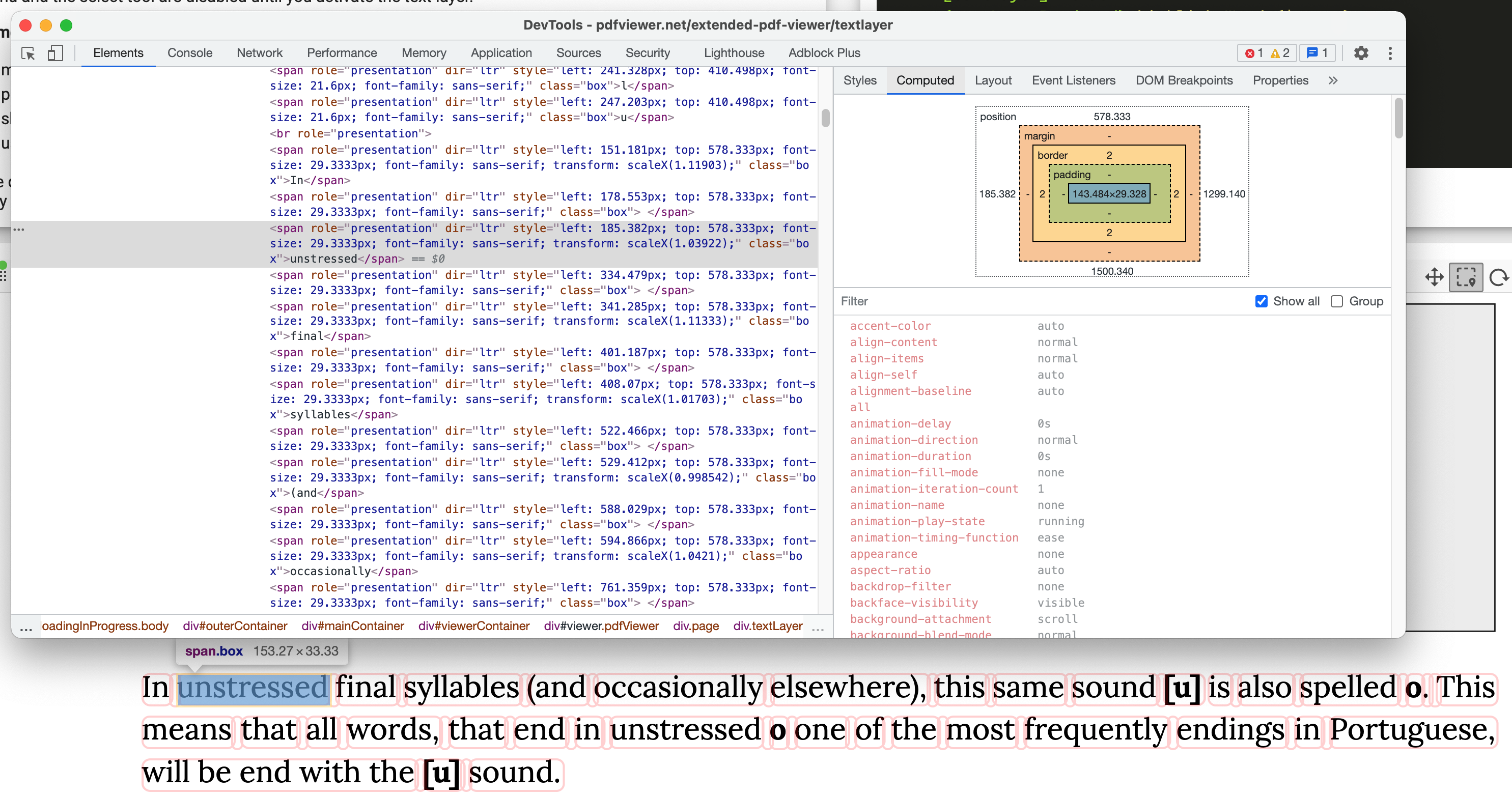
Sounds like a major challenge. Columnar selection is easy in VS Code because it's using a fixed-width font (at least by default). PDF files typically use variable-width fonts, so unless you're rendering a table, there no such thing as a column. You'll have to deal with characters that are partially in the selection range and partially outside. ngx-extended-pdf-viewer in general and pdf.js in particular are ill prepare to support such a selection because they use the default text selection of the browser. You'd have to implement a non-standard selection. I suppose that's possible, but it needs some programming. The selection API (https://developer.mozilla.org/en-US/docs/Web/API/Selection) allows you to select multiple texts simultaneously. So all you need to do is to determine the characters inside the selection area and to mark them using the selection area. But finding out which character is inside requires some effort, too. pdf.js renders text snippets - roughly at word boundaries, but you can't rely on that. You can read the coordinates of the text snippets in the DOM of the text layer:
So using a bit of extrapolation and guesswork, you can calculate which characters of the text snippet are inside the selection area. But as long as you're using variable-width fonts, that's not 100% accurate. If you need a more accurate solution, you'd probably have to dive deep into the implementation of the pdf.js rendering engine. That's something I've successfully avoided so far. :) |
Beta Was this translation helpful? Give feedback.
-
|
Thank you for the explanation. It helps me search in the appropriate module for a solution. Wish me luck! |
Beta Was this translation helpful? Give feedback.
Sounds like a major challenge. Columnar selection is easy in VS Code because it's using a fixed-width font (at least by default). PDF files typically use variable-width fonts, so unless you're rendering a table, there no such thing as a column. You'll have to deal with characters that are partially in the selection range and partially outside.
ngx-extended-pdf-viewer in general and pdf.js in particular are ill prepare to support such a selection because they use the default text selection of the browser. You'd have to implement a non-standard selection. I suppose that's possible, but it needs some programming. The selection API (https://developer.mozilla.org/en-US/docs/Web/API/Selection) …