Support for Eagle / Fusion 360 Electronics #216
Conversation
This adds a third parser for JSON files produced from Eagle or Fusion 360 Electronics using the ULP available at https://github.com/Funkenjaeger/brd2json
|
Also, just wanted to say thank you to @qu1ck and other contributors for this incredible tool! Incidentally, I created a very analogous tool (gerber_pnp_vis) a couple of months ago, not realizing at the time that this one existed. I'm blown away by the maturity level and feature set of this tool, which inspired me to try to make it compatible with the ECAD software package I use rather than spend a lot more effort trying to reinvent the wheel. There are just a couple of small features that I miss in this tool, but once I get my feet under me I look forward to being able to contribute changes to address those. |
There was a problem hiding this comment.
This is great, thanks for contributing!
I like the idea and there are no major issues with the approach but I'd like to make it more generic.
There is nothing really eagle specific in this parser, except that it searches for "_source": "eagle" attribute. We should call it generic json parser and instead add "type": "interactivehtmlbom pcbdata", "spec_version": 1 attributes. That way any ECAD package with scripting support can generate this data and directly integrate with ibom. spec_version is for the future in case there is a need to make incompatible format changes.
Also we need to think ahead how extra field data will be supported. Probably easiest is to add "extra_fields" dict to Component. Current architecture of handling extra data is kicad specific and a bit awkward but I'd like to move in a more generic direction here too. But it's fine if you don't want to tackle everything, having just a generic json parser with no extra features is a good start.
|
@qu1ck thank you for the feedback - I don't disagree with any of it. I took care of the simple stylistic fixes in a635ba5, and I'll take a stab at genericizing the JSON parser tomorrow. While I'm at it making both this more generic (both in this tool and in the JSON format), do you think it's worth keeping the '_type' attribute that I added to the 'components' data object in the JSON? In retrospect, it seems like it may be superfluous. I'm happy to brainstorm on the extra field data, but I'm not familiar enough yet to feel confident in trying to solve it myself. |
…ic and more robust error handling
|
Alright, I took a stab at genericizing this in 41cbc46. All references to Eagle are now generic, and each object (the top-level JSON object, and the "pcbdata" and "components" objects within it) has a _type defined: I didn't put a _spec_version on the top level - technically the JSON parser would be able to handle the case where the "pcbdata" and "components" objects use different _spec_version values. I'm not sure if that is a good or bad thing - other than needing a 1:1 mapping between the elements of the While I was at it, I added error checking and handling which should gracefully error out on issues with any of the _type and/or _spec_version fields (either missing, or invalid value) An updated sample JSON file is attached: |
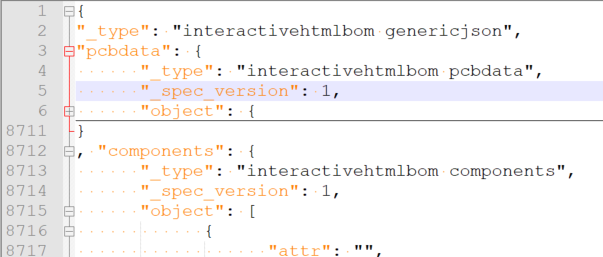
|
There is no need for individual type or spec version for subfields. Also no need to wrap data in "object" field. I was thinking of following structure for the whole file: Regarding validation, it would be ideal to have formal json schema and validate it using jsonschema lib (https://python-jsonschema.readthedocs.io/en/stable/). But we can do that as a next step. |
This is a case where I structured the JSON object to simplify parsing, but it doesn't result in the most concise possible JSON representation (for better or worse). Here's the reason I did it the way that I did - the JSONDecoder seems to operate recursively, so on the call of I suppose another option would be to ditch the custom JSON decoder entirely, let the whole file be parsed by the vanilla JSON decoder, which will turn the 'components' object into a list of dicts - and then create a list of Components from it after the fact. I can do it that way if you prefer.
I agree, and I started looking at that as I was putting this together. I'm game to tackle that once we get the initial implementation laying flat. |
Yes, that's what I was thinking.
Sounds good. |
|
OK, change has been made. |
If you need data validation, why not to opt forPydantic instead? |
I will take a closer look at implementing a schema tonight. At first glance it doesn't seem too complex - in which case I'll try to work it into this PR. If it looks like a bigger job than anticipated then I'll probably mark this PR ready for review and look to submit schema changes in a future one. Also, here's another sample JSON in the latest format: |
@martincolladofab, Honest question - what would be the advantage of going that route? My initial impression of pydantic is that the key selling point is being able to define the model using 'pure, canonical python' which seems like it would be really convenient if the 'pcbdata' and 'components' (and all the constituent objects within them) were already defined as types elsewhere in the code that I could simply reference - but they're not (other than in human-readable format in DATAFORMAT.md) I'm not trying to be difficult, I just genuinely don't know and may very well be missing something. |
|
Having a json schema is also much more useful for integrators and will not limit them to python like pydantic would. @Funkenjaeger I was looking at potential changes to the pcbdata structure that I would need to make for future features. The only one I can think of right now is support for all layers (currently only silk and fab are baked in). I think it's prudent to make that change before schema is finalized. Give me a day or two to think about this a bit more and I'll let you know about any (likely minor) changes. |
Sure thing. While you're at it, do you want to roll in a change for extra field data as you mentioned above? I've already got at least 2 different use cases for which I want to add extra column(s), so if that's something you're looking to change (relative to how you did it in your Keithley 1950 option board demo) it would be nice to get the new way implemented first. If the full implementation of such a change is too much to tackle immediately, I can at least provision for it in the JSON schema here if we can settle on a data structure. |
d43bcfa to
9bbceae
Compare
|
Initial cut at schema and validation using jsonschema lib is in place, using the existing object structure. I will revisit once changes to the object structure are decided. |
|
I just remembered, in my example JSON data file I don't have any entries in certain fields of pcbdata (fabrication, bom, font_data) because my ULP doesn't populate those yet (and they seem to be optional) - and since the schema was generated from that data file, those fields aren't adequately defined in the schema yet. I'll work on addressing that soon. |
|
I've updated the schema manually - it should now cover more or less everything defined in DATAFORMAT.md. I'm standing by to revise as needed once you decide on any format changes to pcbdata, etc. |
|
@qu1ck, on another branch ( https://github.com/Funkenjaeger/InteractiveHtmlBom/tree/genericjson_extra_fields ) I took a stab at adding support for extra_fields with generic JSON.
Rather than modify Let me know if this is anywhere close to what you had in mind. |
Pushed all parsing of extra_fields data down into the respective parsers. This includes some experimental code associated with GenericJsonParser, as well as the existing netlist-based (kicad-specific) code that was in ibom.py
|
Okay, I think I've addressed everything here, both in the schema and the actual ibom python code. I pushed handling of extra_fields down into the respective parsers. This removed all the GenericJsonParser-specific code that I had previously added to the core code in ibom.py, and by the same rationale also removed the existing netlist-related code that was previously there - on the basis that that code is inherently parser-specific. I made the assumption that the EasyEDA workflow doesn't support extra_fields. If that's not true (e.g. if it supports a netlist exactly like how it works for kicad) I can easily change it. Looking back at your comments, I probably didn't implement it exactly as you envisioned (extra_fields is processed as part of parse() rather than via a separate call to extra_data_func, and in GenericJsonParser I just dealt with extra_fields inline without doing anything with extra_data_func at all). It's entirely possible that I've missed the point of why extra_data_func exists, in which case feel free to set me straight. |
There was a problem hiding this comment.
Great progress.
My main concern is duplicating the information in EcadParser.parse() return fields. Extra data is already in components, there is no need to return it separately. I'd like to instead have kicad parser be changed to put the extra data into Component objects. It will simplify core ibom logic too.
Another thing is extra fields will currently be unusable if plugin is called with --show-dialog because EcadParser.extra_data_func() is not overriden. GUI uses that to determine list of available extra fields. Like I said earlier, this function probably should be a proper method instead of a lambda. Do you have a sample json file with extra fields I can test?
I will not block this PR on making GUI work, this can be addressed later along with necessary refactoring.
Yeah, EasyEDA doesn't support extra fields, all good.
Like I commented above, it's separate because GUI uses it to show list of available fields. |
Revert to returning extra_fields only within components
|
You're right, the way I was returning extra field data was less than optimal. The extra field data that comes in the JSON file will not exactly match specific fields requested for parsing, so I had filtered and returned it separately, but I could just as easily replace that within the components object (standardizing it) instead, so I've reverted to that with 2b46456. Full disclosure, I haven't used (or even seen) the GUI, so admittedly I'm ignorant of that workflow. I'll revisit kicad.py based on your comment regarding footprint_to_component. An updated example JSON with extra_data for testing purposes: |
This one took me longer than expected since I got a little unsure about my implementation and didn't have a way to test it, having never used kicad before. After some false starts I was able to get kicad installed, find an example project, figure out how to run ibom via CLI using the kicad python environment, and find that I needed a PYDEVD_USE_CYTHON=NO environment variable to allow the debugger to connect. I got through my issues, and as far as I can tell, it seems to be working for kicad now - I tested via the CLI, as well as via the GUI using the button within kicad - in both cases with one or more extra fields enabled. Finally, regarding extra_data_func() - I'm inclined to leave that for later. From what I see, it's still usable via the GUI (doesn't error, successfully generates the output file) if the user chooses to do so, it's just that the GUI doesn't report any available extra field data. As such, I think that could be considered a future enhancement rather than a bug. Unless I'm forgetting something, I think that might be everything - pending your review of the latest round of changes, of course. Let me know your thoughts. |
There was a problem hiding this comment.
Looking good, some minor things left.
I tested it and json you attached seems to have bounding box a bit off. I'm guessing the way you calculate it on eagle script side includes some invisible shapes in the box. You can resolve this like I did in EasyEDA parser: calculate bbox ourselves based on edges, fallback to provided bbox if there are none.
All the geometry stuff is already implemented, just look at how EasyEDA parser does it. It's 3 lines of code if you don't count extracting add_drawing_bounding_box() to common.
|
Thank you for a great contribution and sticking through multiple rounds of review. Please let me know when you finish the work on eagle side, I'd like to feature some open source eagle design on demos page. |
|
Great, thank you! I appreciate your patience and assistance throughout the review process. I'll reach back when I've got more implemented. I can write up some documentation to add to the wiki, unless you'd rather handle that. |
|
I will take care of the docs and will also add an integration guide. |
|
@qu1ck I've got the Fusion 360 Electronics side of this more or less feature-complete now. Eagle is still supported (on a branch) minus some features (e.g. polygons) because Autodesk made some non-backwards-compatible changes so it's no longer possible for one script to work fully in both tools. But I digress... I've added support for text (vector fonts only), component outlines and polygons on silkscreen, non-rectangular SMD pads (round and rounded rectangle), copper tracks (incl. vias) and zones with net names, and netlist (extracted from the BRD, no separate file needed), and fixed several latent bugs. Shoutout to @ConnyCola for the help! Let me know if you see anything missing or in need of tweaking. An example board is attached - OK to use as a demo if you're satisfied with it. |
|
It looks good but one thing that's missing is pads don't have net information. To add a demo I need a link to published source files and make sure it's under an open license. Not sure how it would work for fusion, probably a link to autodesk gallery or something? |
|
Good catch, net info on pads was an easy fix. When you say 'published source files', I guess I'm not completely clear on your requirements. If I'm understanding you correctly, you don't want to just host them and provide a direct download link, you want them published somewhere else for you to link to? |
|
Looks great now. One more minor thing, add an empty string to nets array when there are elements on the board with no net info (unconnected pads usually). It's displayed in the table as
Yes, this is fine. I just don't want to host other peoples projects but I need to know that they have open license so that I can host what is essentially a derived work in form of ibom demo page. And I need a link to source files so that others can open the files themselves and see what the bom is created from. |
|
Sounds good. |
|
FYI, added wiki page that lists eagle support and some info on integration |
|
I don't know a better place so just wanted to say thank you to @qu1ck and @Funkenjaeger for getting both tools supported! It's such a fantastic tool and I'm really glad I can enjoy the upstream iBom now. |
This is my attempt to add support for Eagle and Fusion 360 Electronics to InteractiveHtmlBom. This PR adds a third parser for JSON files that can be produced from those tools using a ULP (glorified script) which I created separately, which resides at https://github.com/Funkenjaeger/brd2json
I did 99% of the heavy lifting in the ULP (which runs in Eagle/Fusion), so there's very little that needs to be done within InteractiveHtmlBom to bring in the data. The content in the JSON is structured as closely as I could get to the 'pcbdata' and 'components' objects needed within this tool - the former is able to be directly deserialized by json.load() and used as-is since it's made up of only python native types, while I had to do just a tiny bit of translation on the latter since it uses the custom class InteractiveHtmlBom.ecad.common.Component. I also had to add a little bit of logic to disambiguate JSON files coming from Eagle/Fusion versus those from EasyEDA, since they both use the '.json' extension.
I've made this PR a draft since I'm still working on cleaning up and publishing the corresponding ULP, and I'm also completely open to suggestions on the preferred implementation within InteractiveHtmlBom, or the overall workflow, or whatever. I've got complete creative freedom on the ULP and therefore the format of the JSON, so I can also tweak things there if it would make more sense.
An example JSON file is attached, for testing purposes:
MZMFC v8.zip