项目仓库地址(欢迎 Star ⭐):https://github.com/li-xiu-qi/Text2Video
快速克隆:
git clone https://github.com/li-xiu-qi/Text2Video.git
cd Text2Video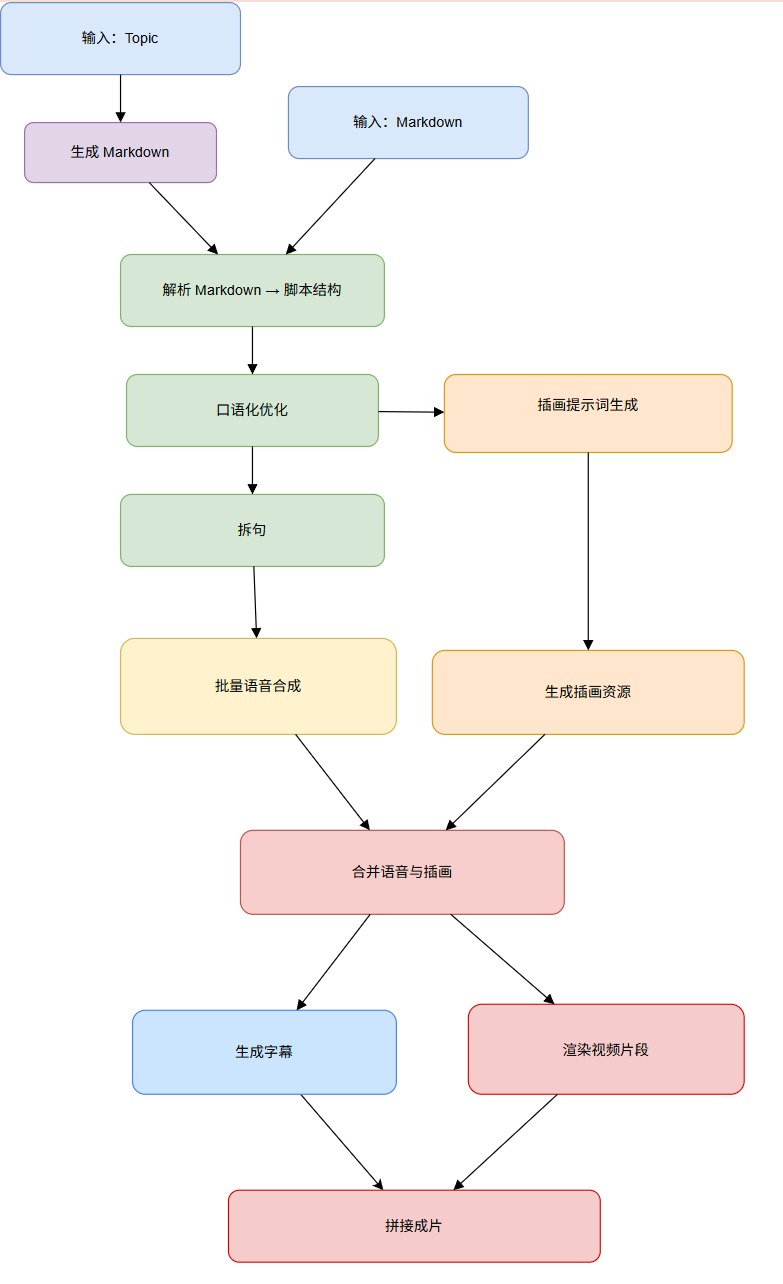
Text2Video 是一个功能强大的端到端视频自动化生成工具,能够从简单的主题或 Markdown 文档快速创建高质量的讲解视频。本工具集成了最新的 AI 技术栈,包括 LLM 脚本生成与优化、TTS 语音合成、AI 图像生成,以及 FFmpeg 视频后处理,为用户提供完整的视频制作解决方案。
- 输入主题关键词,自动生成完整的教学视频
- 支持 Markdown 文档直接转换为视频内容
- LLM 智能脚本生成与口语化优化
- TTS 高质量语音合成
- AI 驱动的插画图片生成
- 智能字幕时间轴计算
- FastAPI 后端服务,支持 RESTful API 调用
- Streamlit Web UI,提供友好的图形界面
- Docker 容器化部署,一键启动服务
Text2Video 提供两种灵活的输入方式,满足不同用户的需求:
-
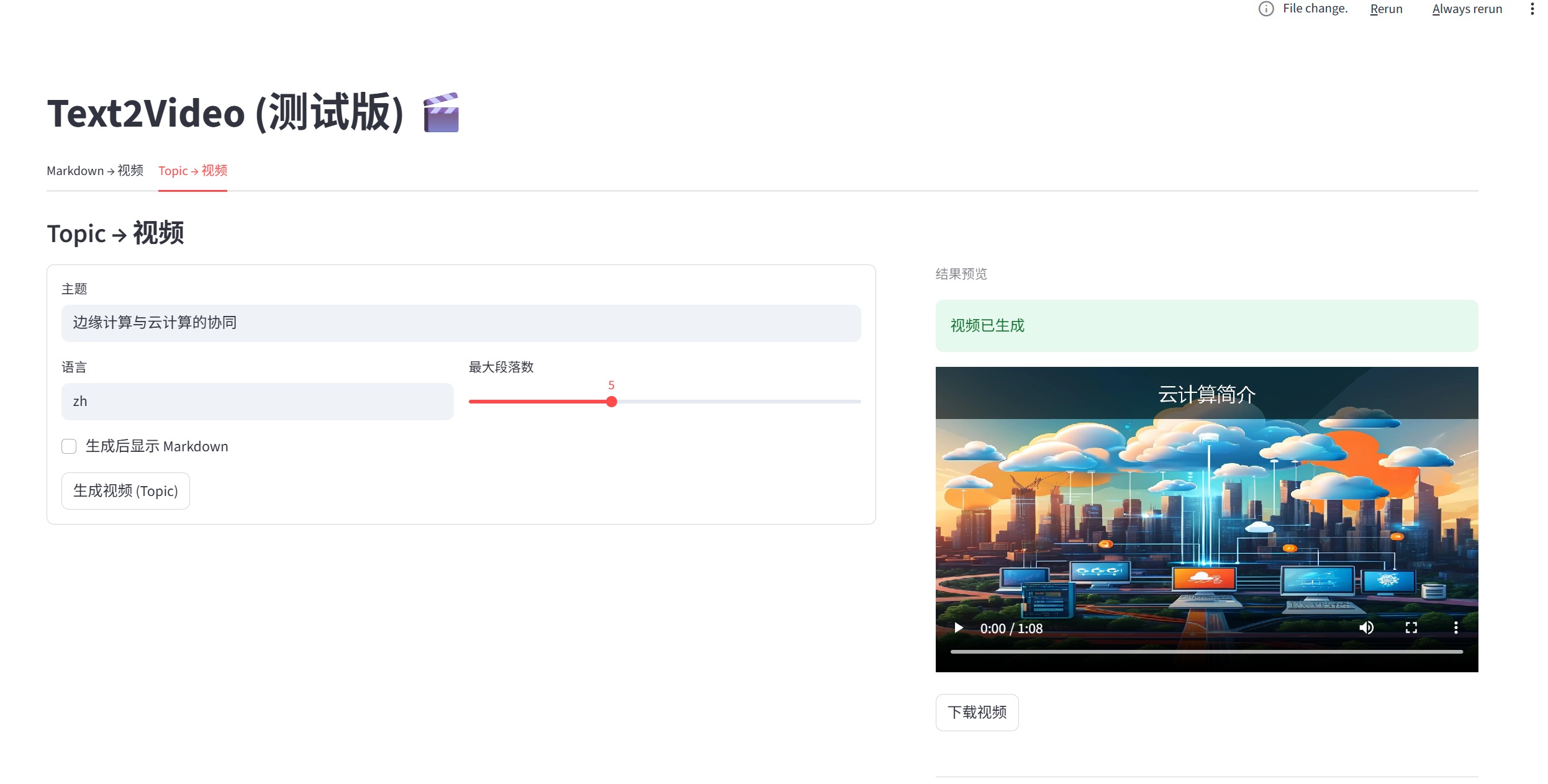
主题驱动模式:
Topic → 自动生成 Markdown → 生成视频- 只需输入一个主题关键词或简短描述
- AI 自动扩展为结构化的 Markdown 内容
- 适合快速创建教学或介绍类视频
-
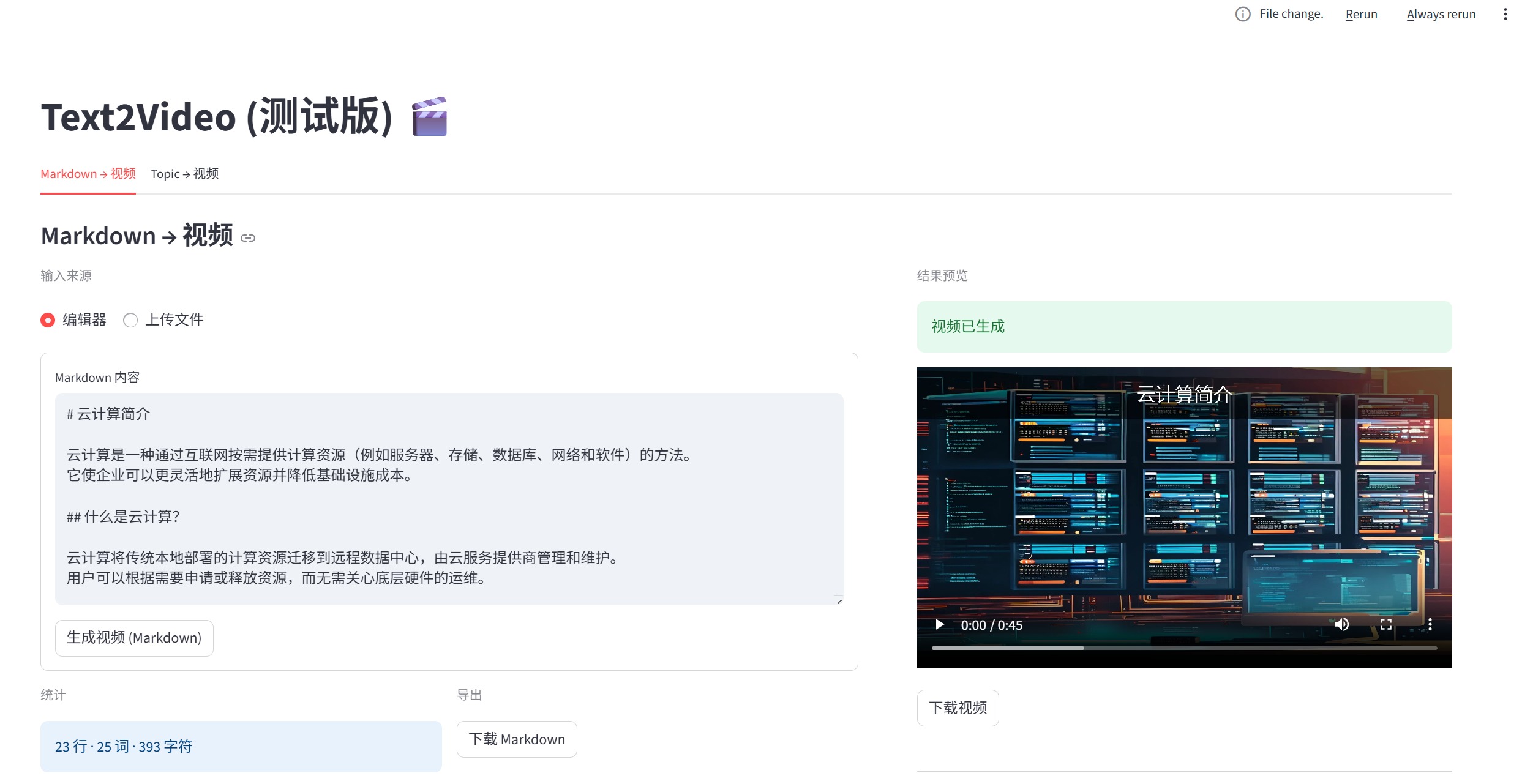
Markdown 直接模式:
Markdown → 直接生成视频- 支持现有 Markdown 文档的直接导入
- 保持原有内容结构和逻辑
- 适合已有文档的视频化转换
项目实现了完整的中间产物持久化策略,确保每个步骤的输出都可追溯和复用:
- 脚本文件:
script_raw.json、script_optimized.json、script_expanded.json - 语音资产:音频文件、时长缓存、语音清单
- 视觉资产:插画提示词、生成的图片文件
- 字幕文件:支持 JSON 和 SRT 双格式输出
- 最终产品:合并后的视频块和完整 MP4 文件
采用抽象接口设计,支持多种 AI 服务提供商的灵活切换:
- LLM Provider:支持不同的大语言模型服务
- TTS Provider:可配置多种语音合成服务
- Image Provider:支持多个 AI 图像生成平台
- 扩展性:轻松添加新的服务提供商支持
在开始使用 Text2Video 之前,请确保您的系统满足以下要求:
- Python 版本:3.11 或更高版本
- 操作系统:支持 Windows、macOS、Linux
FFmpeg 是本项目的核心依赖,用于音视频处理和最终视频合成。
Windows 用户:
- 访问 FFmpeg Builds 下载最新版本
- 解压下载的文件到任意目录(如
C:\ffmpeg) - 将 FFmpeg 的
bin目录添加到系统环境变量 PATH 中 - 打开命令提示符,运行
ffmpeg -version验证安装
macOS 用户:
# 使用 Homebrew 安装
brew install ffmpeg
# 验证安装
ffmpeg -versionLinux 用户:
# Ubuntu/Debian
sudo apt update
sudo apt install ffmpeg
# CentOS/RHEL
sudo yum install ffmpeg
# 验证安装
ffmpeg -version建议在虚拟环境中安装,以避免依赖冲突:
# 创建虚拟环境
python -m venv .venv
# 激活虚拟环境(Windows)
.venv\Scripts\activate
# 激活虚拟环境(macOS/Linux)
source .venv/bin/activate
# 升级 pip 到最新版本
python -m pip install -U pip
# 安装项目依赖
pip install .如果您使用现代化的 UV 包管理器,可以更快速地完成环境配置:
# 一键同步所有依赖
uv sync
# 自动创建并激活虚拟环境
uv run python main.pyUV 的优势:
- 更快的依赖解析和安装速度
- 自动虚拟环境管理
- 更好的依赖冲突检测
本项目支持两类配置来源(从高到低优先级):
config.yaml(如果存在则优先使用;适合本地开发或容器挂载统一配置)- 环境变量(包括
.env中的变量) - 代码内置默认值(兜底,不推荐依赖)
也就是说:config.yaml 中的同名键会覆盖环境变量;未出现在 config.yaml 的键再回退到环境变量 / .env;仍缺失才使用默认值。
仓库提供模板文件:config.example.yaml 与 .env.example。请复制后填写真实值:
cp config.example.yaml config.yaml
cp .env.example .env建议:
config.yaml与.env不要提交包含真实秘钥的版本;生产环境更倾向仅用环境变量(例如 CI/CD 注入)。
一个典型的 config.yaml 示例:
GUIJI_API_KEY: "sk-xxxx"
GUIJI_BASE_URL: "https://api.siliconflow.cn/v1"
GUIJI_IMAGE_BASE_URL: "https://api.siliconflow.cn/v1/images/generations"
GUIJI_IMAGE_MODEL: "Kwai-Kolors/Kolors"
GUIJI_CHAT_MODEL: "Qwen/Qwen2.5-32B-Instruct"
IMAGE_IPM: 2 # 每分钟图片生成速率限制
VIDEO_WIDTH: 1280 # (可选) 覆盖默认视频宽度
VIDEO_HEIGHT: 720 # (可选) 覆盖默认视频高度
VIDEO_DEBUG: false # (可选) 生成调试级日志/中间帧如果同时在 .env 写了 GUIJI_IMAGE_MODEL=OtherModel,但 config.yaml 中已有该键,最终仍以 config.yaml 的值为准。
快速验证优先级(应打印出 config.yaml 中的值):
python - <<"PY"
from app.core.config import CONFIG
print("chat_model:", CONFIG.model.chat_model)
print("image_model:", CONFIG.model.image_model)
print("run_id:", CONFIG.path.run_id)
PY最少需要提供 API Key。你可以:
- 只写在
config.yaml(推荐本地调试) - 或只写在
.env(推荐生产 / 容器通过环境注入) - 或两者都写(
config.yaml优先生效)
下面仍以 .env 形式给出示例(与 config.yaml 键名一致,可互换):
本项目默认使用硅基流动作为 AI 服务提供商,提供高质量的 LLM、TTS 和图像生成服务。
- 访问 硅基流动官网 注册账号
- 在控制台创建 API Key
- 将 API Key 配置到
.env文件中
# ===========================================
# 硅基流动 API 配置(必填)
# ===========================================
GUIJI_API_KEY=sk-your-api-key-here
GUIJI_BASE_URL=https://api.siliconflow.cn/v1
# ===========================================
# AI 模型配置
# ===========================================
# 大语言模型(用于脚本生成和优化)
GUIJI_CHAT_MODEL=Qwen/Qwen2.5-7B-Instruct
# 图像生成模型(用于插画创建)
GUIJI_IMAGE_MODEL=Kwai-Kolors/Kolors
# 语音合成模型(用于配音生成)
GUIJI_TTS_MODEL=FunAudioLLM/CosyVoice2-0.5B
创建或修改 config.yaml / .env 后,可以通过以下方式验证加载是否成功:
# 测试 API 连接
python -c "from app.core.config import settings; print('✅ 配置加载成功')"
# 测试硅基流动 API
python tests/test_api_routes.pyText2Video 提供两种运行模式,您可以根据需求选择合适的方式:
FastAPI 服务提供 RESTful API 接口,适合集成到其他应用或进行批量处理。
# 方式 1:直接运行(推荐)
python main.py
# 方式 2:使用 uvicorn(更多自定义选项)
uvicorn main:app --reload --host 0.0.0.0 --port 8000服务启动后,访问以下地址:
- API 文档:http://127.0.0.1:8000/docs (Swagger UI)
- 备用文档:http://127.0.0.1:8000/redoc (ReDoc)
Streamlit 提供友好的图形界面,适合非技术用户和快速原型验证。
streamlit run streamlit.app.py启动后浏览器会自动打开,界面包含两个功能模块:
- 直接输入 Markdown 内容
- 支持文件上传(.md 格式)
- 一键生成视频,实时查看进度
- 输入主题关键词或描述
- 配置生成参数(段落数、语言等)
- AI 自动扩展为 Markdown 后生成视频
Web UI 特色功能:
- 实时进度显示
- 中间产物预览
- 视频在线播放
- 一键下载结果
💡 提示:Web UI 默认将输出保存到
output/webui/目录,便于管理和查找。
Docker 镜像内已预装 FFmpeg 和中文字体,支持开箱即用的容器化部署。
docker build -t text2video .docker build -t text2video \
--build-arg PIP_INDEX_URL=https://mirrors.aliyun.com/pypi/simple \
--build-arg PIP_EXTRA_INDEX_URL=https://pypi.org/simple \
.启动 FastAPI 后端服务:
docker run --rm -it \
-p 8000:8000 \
-e RUN_MODE=api \
--env-file .env \
-v "%CD%\output":/app/output \
text2video启动 Streamlit 界面:
docker run --rm -it \
-p 8501:8501 \
-e RUN_MODE=ui \
--env-file .env \
-v "%CD%\output":/app/output \
text2video使用 Docker Compose 可以同时运行 API 和 Web UI 服务:
# 启动所有服务
docker compose up -d --build
# 查看服务状态
docker compose ps
# 停止所有服务
docker compose down服务访问地址:
- API 服务:http://localhost:8000
- Web UI:http://localhost:8501
# 查看 API 服务日志
docker compose logs -f api
# 查看 Web UI 服务日志
docker compose logs -f ui
# 查看所有服务日志
docker compose logs -f配置挂载策略:
- 你可以选择:
- 仅传递环境变量(
--env-file .env或 Compose 的env_file) - 挂载一个
config.yaml(覆盖内部同名值) - 两者并存:当需要在同一镜像下给不同实例提供差异化配置时,可用不同
config.yaml。
- 仅传递环境变量(
示例(仅使用 .env 环境变量):
docker run --rm -it ^
-p 8000:8000 ^
-e RUN_MODE=api ^
--env-file .env ^
-v "%CD%\output":/app/output ^
text2video示例(仅挂载本地 config.yaml):
docker run --rm -it ^
-p 8000:8000 ^
-e RUN_MODE=api ^
-v "%CD%\config.yaml":/app/config.yaml ^
-v "%CD%\output":/app/output ^
text2video示例(挂载本地 config.yaml + .env):
docker run --rm -it \
-p 8000:8000 \
-e RUN_MODE=api \
--env-file .env \
-v "%CD%\config.yaml":/app/config.yaml \
-v "%CD%\output":/app/output \
text2video注意:容器内若存在
/app/config.yaml,它将覆盖.env中的同名变量。
Text2Video 提供简洁易用的 RESTful API,支持两种视频生成模式。
| 端点 | 方法 | 功能 | 响应格式 |
|---|---|---|---|
/video/from-topic |
POST | 从主题生成视频 | JSON |
/video/from-markdown |
POST | 从 Markdown 生成视频 | MP4 二进制流 |
从主题关键词自动生成视频内容。
curl -X POST "http://127.0.0.1:8000/video/from-topic" \
-H "Content-Type: application/json" \
-d '{
"topic": "边缘计算与云计算的协同",
"language": "zh",
"max_sections": 5,
"run_id": "my-custom-id"
}'| 参数 | 类型 | 必填 | 说明 | 默认值 |
|---|---|---|---|---|
topic |
string | ✅ | 视频主题或关键词 | - |
language |
string | ❌ | 内容语言(zh/en) | "zh" |
max_sections |
integer | ❌ | 最大章节数量 | 5 |
run_id |
string | ❌ | 自定义运行ID | 随机生成 |
{
"output_path": "c:/path/to/output/abc123/final_video.mp4",
"blocks_count": 12,
"run_id": "abc123",
"duration": 185.6,
"status": "success"
}直接从 Markdown 内容生成视频文件。
curl -X POST "http://127.0.0.1:8000/video/from-markdown" \
-H "Content-Type: application/json" \
-d '{
"markdown": "# 人工智能简介\n\n人工智能是计算机科学的一个分支...",
"output": "ai-intro-video.mp4"
}' \
-o result.mp4| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
markdown |
string | ✅ | Markdown 格式的内容 |
output |
string | ❌ | 输出文件名或路径 |
run_id |
string | ❌ | 自定义运行ID |
直接返回 MP4 视频文件的二进制流,适合直接保存或下载。
- 批量处理:可通过脚本循环调用 API 实现批量视频生成
- 进度监控:通过
run_id可以在文件系统中跟踪生成进度 - 输出管理:使用自定义
output参数组织生成的视频文件
所有产物默认写入 output/<run_id>/:
script_raw.json/script_optimized.json/script_expanded.jsonspeech/:speech_manifest.json(可复用,避免重复 TTS)duration_cache.json(探测到的音频时长缓存)
images/:illustration_prompts.json(插画提示)illustration_assets.json(生成图片的本地路径等)
blocks_merged.json:合并后的语音+图片块subtitles.json/subtitles.srtsegments/:临时视频片段与资源final_video.mp4:最终视频
说明:RUN_ID 不指定时会随机生成短 UUID 用于隔离;Web UI 默认将其固定为 webui。
整体流程是:从主题或 Markdown 开始,先用 LLM 生成/口语化优化脚本并按语音粒度切分句子;随后批量合成 TTS 音频并缓存探测到的时长,同时用 LLM 产出插画提示并通过图片模型生成配图;将语音与图片按顺序合并为 blocks 并计算字幕时间轴(JSON/SRT);最后为每个标题/句子渲染字幕面板叠加到背景图、与对应音频合成片段,使用 ffmpeg concat 拼接成 MP4 输出,过程中会把脚本、清单、图片与中间结果全部持久化,便于复用与调试。
app/
core/ # 配置、流水线、插画、合并、视频装配
providers/ # LLM / TTS / Image Provider 实现
routers/ # FastAPI 路由
services/ # 业务服务封装(供路由使用)
main.py # FastAPI 入口
streamlit.app.py # Web UI 入口
pyproject.toml # 依赖与元数据
output/ # 运行产物(按 run_id 隔离)
下面的提示词是用来生成插画的。
def generate_illustration_prompts(script_json: str, llm: LLMProvider, model: str | None = None) -> list[dict]:
"""调用 LLM 生成插图提示 JSON 数组。"""
system_message = (
"您是一位插图提示生成专家,专注于为微课程生成详细的插图提示。"
)
prompt = f"""
### 任务
生成关于 {script_json} 的插图。返回仅包含多个插图详细信息的 JSON 数组。
### 插图描述要素:
- **主题:** 中心概念。
- **描述:** 详细叙述重点元素、情感和氛围。
- **场景:** 特定环境(如自然、城市、太空),包括颜色、光线和情绪。
- **对象:** 主要主题和特征(如人、动物、物体)。
- **动作:** 对象的动态(如飞行、跳跃、闲逛)。
- **风格:** 艺术技巧(如抽象、超现实主义、水彩、矢量)。
- **细节:** 其他特定信息(如纹理、背景元素)。
### 生成的提示结构:
描述, 场景, 包含对象, 动作. 以风格呈现, 强调细节。
### 输出格式要求
\```json
[
{{
"illustration_id": 1,
"title": "阳光明媚的日子",
"description": "一幅富有创意的数字艺术作品,描绘了一只由埃菲尔铁塔构建的长颈鹿。"
}},
{{
"illustration_id": 2,
"title": "繁星之夜",
"description": "一幅黑暗幻想肖像,呈现了一匹马奔跑在风暴中,背景火焰般的景观。"
}}
]
\```
输出格式为JSON。不包含任何额外的文字、解释或评论。
"""
messages = [
{"role": "system", "content": system_message},
{"role": "user", "content": prompt},
]
raw = llm.chat(messages, model=model) # 允许 provider 内部忽略 model
raw = raw.strip()
if raw.startswith("```json"):
raw = raw[len("```json"):].strip()
if raw.endswith("```"):
raw = raw[:-3].strip()
try:
data = json.loads(raw)
except Exception as e:
raise ValueError(f"插图提示解析失败: {raw[:200]} ... -> {e}") from e
return data下面是脚本口语化处理的提示词。
def optimize_script_for_speech(script_items: list[dict[str, str]], llm: LLMProvider) -> list[dict[str, str]]:
"""调用 LLM 对 content 口语化。"""
system_message = "您是录音稿专家。"
prompt = f"""处理以下 JSON 中的 content 字段,并将内容转换为适合录音的纯文本形式。
返回处理后的 JSON,不要任何额外的说明。内容格式要求:
1. 对于英文的专有术语缩写,替换为全称。
2. 去除星号、井号等 Markdown 格式。
3. 去除换行符和段落分隔。
4. 对于复杂的长难句,使用中文句号分割,便于口语表达。
content 中的内容使用于发言使用。
下面的内容是待处理的 JSON:
{json.dumps(script_items, ensure_ascii=False)}
输出格式为 JSON。不包含任何额外的文字、解释或评论。
非常重要:请严格返回可被 json.loads() 解析的 JSON。注意事项:
- 使用英文逗号分隔数组中的对象,数组元素之间不能缺少逗号。
- 字符串必须使用双引号。
- 不要在 JSON 外添加任何说明性文字或代码块说明(例如 ```json ```)。
下面给出一个合法输出示例(仅供格式参考):
[
{{"title": "云计算简介", "content": "云计算是一种通过互联网按需提供计算资源,例如服务器、存储、数据库、网络和软件。它使企业可以更灵活地扩展资源并降低基础设施成本。"}},
{{"title": "什么是云计算", "content": "云计算将传统本地部署的计算资源迁移到远程数据中心,由云服务提供商管理和维护。用户可以根据需要申请或释放资源,而无需关心底层硬件的运维。"}}
]
"""
messages = [
{"role": "system", "content": system_message},
{"role": "user", "content": prompt},
]
raw = llm.chat(messages)
raw = raw.strip()
if raw.startswith("```"):
# 去掉 ```json 包装
raw = re.sub(r'^```json', '', raw)
raw = raw.removeprefix('```').strip('`')
try:
data = json.loads(raw)
except Exception as e: # 容错:如果模型返回非纯 JSON
raise ValueError(f"LLM 返回内容解析失败: {raw[:200]} ... -> {e}") from e
return data下面是脚本生成的部分提示词。
_FEW_SHOT_EXAMPLE = """
## 云计算简介
云计算是一种通过互联网按需提供计算资源(例如服务器、存储、数据库、网络和软件)的方法。
它使企业可以更灵活地扩展资源并降低基础设施成本。
## 什么是云计算?
云计算将传统本地部署的计算资源迁移到远程数据中心,由云服务提供商管理和维护。
用户可以根据需要申请或释放资源,而无需关心底层硬件的运维。
## 云计算的主要类型
- 公有云:由第三方云服务提供商向多个租户提供服务。
- 私有云:为单个组织专属使用,通常部署在防火墙后面。
- 混合云:结合公有云与私有云的优势,支持在不同环境之间迁移工作负载。
## 云计算的优点
- 弹性伸缩:根据负载动态调整资源,避免资源浪费。
- 成本优化:按需付费,减少初始投资和运维成本。
- 高可用性:多可用区和灾备方案提升业务连续性。
了解这些基本概念后,你就可以开始评估云服务提供商并设计适合自己业务的云架构了。
"""
_SYSTEM_INSTRUCTION = """
你是一个专业的视频脚本撰写助手, 需要基于给定的主题或要点, 生成结构化的 Markdown 内容。
要求:
1) 偏教程风格, 面向初学者;
2) 使用若干 ## 二级标题拆分要点;
3) 语言自然、口语化、利于后续 TTS 配音;
4) 避免过长段落, 每段 1-3 句;
5) 不要添加额外的解释性前后缀。
"""语音生成的部分,使用的是来自硅基流动的一个tts模型实现。 如下代码所示:
def synthesize(
self,
text: str,
*,
voice: str | None = None,
out_dir: str = "audio_output",
filename: Optional[str] = None,
response_format: str = "mp3",
sample_rate: int = 44100,
stream: bool = False,
speed: float = 1.0,
gain: float = 0.0,
) -> str:
"""合成单条文本语音并保存为本地文件,返回绝对路径。"""
if not text.strip():
raise ValueError("text 不能为空")
os.makedirs(out_dir, exist_ok=True)
base_name = filename or f"guiji_{int(time.time())}_{uuid4().hex[:8]}"
url = "https://api.siliconflow.cn/v1/audio/speech"
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json",
}
payload = {
"model": self.model,
"input": text,
"response_format": response_format,
"sample_rate": sample_rate,
"stream": stream,
"speed": speed,
"gain": gain,
}
use_voice = voice or self.default_voice
if use_voice:
payload["voice"] = f"{self.model}:{use_voice}"
resp = requests.post(url, headers=headers, json=payload, timeout=self.timeout)
if resp.status_code != 200:
raise RuntimeError(
f"guiji TTS 请求失败: {resp.status_code} {resp.text[:200]}"
)
audio_path = os.path.abspath(os.path.join(out_dir, f"{base_name}.{response_format}"))
if os.path.exists(audio_path): # 极少数情况下名称冲突
audio_path = os.path.abspath(
os.path.join(out_dir, f"{base_name}_{uuid4().hex[:6]}.{response_format}")
)
with open(audio_path, "wb") as f:
f.write(resp.content)
return audio_path在生成语音之后我们需要获取语音的时长,这里使用了一个第三方库:pydub 来实现。 如下代码所示:
from typing import Optional
from pydub import AudioSegment
def get_audio_duration(audio_path: str) -> float:
"""获取音频时长,单位秒"""
audio = AudioSegment.from_file(audio_path)
return audio.duration_seconds
def probe_duration(path: str) -> Optional[float]:
"""探测音频文件时长(秒)。失败返回 None,由调用方再做估算兜底。"""
try:
audio = AudioSegment.from_file(path)
return len(audio) / 1000.0
except Exception:
return None
if __name__ == "__main__":
audio_path = r"C:\Users\ke\Documents\projects\python_projects\Text2Video\tests\audio_output\guiji_1757503555_9b16f38e.mp3"
duration = get_audio_duration(audio_path)
print(f"音频时长: {duration:.2f} 秒")
# 试试probe_duration
duration2 = probe_duration(audio_path)
print(f"探测时长: {duration2:.2f} 秒")我们这里使用了两种方式来获取音频时长,一种是通过使用duration_seconds属性,另一种是通过使用pydub库的AudioSegment类获取里面的ms,也就是毫秒数,然后除以1000.0,得到秒数。当然,你还可以使用ffprobe读取秒数,比如下面的命令:
ffprobe -v error -show_entries format=duration -of default=noprint_wrappers=1:nokey=1 "test.mp3"运行上面的命令之后会直接输出:
3.082438也可以使用ffmpeg + findstr的方式获取对应的秒数。
ffmpeg -i "test.mp3" 2>&1 | findstr /C:"Duration"
输出结果大概是这样的:
Duration: 00:00:03.08, start: 0.000000, bitrate: 131 kb/s不过两者都属于 FFmpeg 套件,通常一起安装并放在 PATH 中。所以我推荐你使用ffprobe即可。
他们两者的区别:
ffmpeg是一个功能丰富的多媒体处理工具,负责编码/解码、转码、复用/解复用、滤镜处理(裁剪、缩放、overlay、转场、转码等)以及从输入生成输出的所有实际处理工作。典型场景:把图片和音频合成视频、把 mp3 转 wav、裁剪视频、添加字幕等。
ffprobe是一个用于“探测/读取媒体元数据”的工具,轻量、专注于报告文件信息(时长、格式、流信息、比特率、帧率等)。不做转码,只读信息,便于脚本里用来判断和决策(例如读取音频时长)。
下面是一个通过硅基流动的文本生成图片的一个请求示例,代码如下所示:
import requests
import os
import time
from urllib.parse import urlparse, unquote
from collections import deque
import threading
class ImageGenerator:
"""图像生成器类,支持 IPM(images per minute)速率限制并将生成的第一张图片下载到本地。
使用示例:
g = ImageGenerator(api_key, ipm=2)
path = g.generate_and_save(prompt)
"""
def __init__(
self,
api_key: str,
model: str = "Kwai-Kolors/Kolors",
base_url: str = "https://api.siliconflow.cn/v1/images/generations",
ipm: int = 2,
output_dir: str = "output_images",
timeout: int = 30,
):
self.api_key = api_key
self.model = model
self.base_url = base_url
self.ipm = max(1, int(ipm))
self.output_dir = output_dir
self.timeout = timeout
# deque 用于记录一分钟内的调用时间戳
self._calls = deque()
self._lock = threading.Lock()
def _wait_for_slot(self):
"""如果一分钟内调用已达 ipm,等待至有可用槽位为止。"""
with self._lock:
now = time.time()
# 清理 60 秒之前的时间戳
while self._calls and now - self._calls[0] >= 60:
self._calls.popleft()
if len(self._calls) < self.ipm:
# 还有槽位,记录当前调用时间戳并返回
self._calls.append(now)
return
# 已满,计算需等待时间
earliest = self._calls[0]
wait = 60 - (now - earliest)
# 在锁外睡眠,避免阻塞其他线程的检查
if wait > 0:
time.sleep(wait)
# 递归/循环直到能加入
return self._wait_for_slot()
def _extract_first_image_url(self, resp_json: dict) -> str:
img_url = None
if isinstance(resp_json, dict):
if resp_json.get("images") and isinstance(resp_json["images"], list):
img_url = resp_json["images"][0].get("url")
if not img_url and resp_json.get("data") and isinstance(resp_json["data"], list):
img_url = resp_json["data"][0].get("url")
if not img_url:
for v in resp_json.values():
if isinstance(v, list):
for item in v:
if isinstance(item, dict) and item.get("url"):
img_url = item.get("url")
break
if img_url:
break
if not img_url:
raise ValueError("未能在响应中找到图片 URL,响应内容: " + str(resp_json))
return img_url
def _download_image(self, img_url: str) -> str:
os.makedirs(self.output_dir, exist_ok=True)
path = urlparse(img_url).path
unquoted_path = unquote(path)
filename = os.path.basename(unquoted_path)
if not filename:
filename = f"image_{int(time.time())}.png"
file_path = os.path.join(self.output_dir, filename)
r = requests.get(img_url, timeout=60)
r.raise_for_status()
with open(file_path, "wb") as f:
f.write(r.content)
return os.path.abspath(file_path)
def generate_and_save(
self,
prompt: str,
batch_size: int = 1,
image_size: str = "1024x1024",
num_inference_steps: int = 20,
guidance_scale: float = 7.5,
) -> str:
"""生成图片并保存第一张,返回本地绝对路径。该方法会受 IPM 限制控制。
可能抛出的异常:requests.HTTPError、ValueError 等。
"""
# 等待可用的调用槽位(速率控制)
self._wait_for_slot()
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json",
}
payload = {
"model": self.model,
"prompt": prompt,
"image_size": image_size,
"batch_size": batch_size,
"num_inference_steps": num_inference_steps,
"guidance_scale": guidance_scale,
}
resp = requests.post(self.base_url, headers=headers, json=payload, timeout=self.timeout)
resp.raise_for_status()
resp_json = resp.json()
img_url = self._extract_first_image_url(resp_json)
return self._download_image(img_url)
if __name__ == "__main__":
import os
from dotenv import load_dotenv
load_dotenv()
API_KEY = os.getenv("GUIJI_KEY")
gen = ImageGenerator(api_key=API_KEY, ipm=2, output_dir="output_images")
try:
# 示例:连续调用两次,IPM=2 会限制每分钟不超过 2 次
p1 = gen.generate_and_save(prompt="一幅美丽的风景画,画中有山脉和河流,采用吉卜力工作室的风格")
print("已保存图片到:", p1)
p2 = gen.generate_and_save(prompt="同一主题的另一幅构图,黄昏光线,柔和色彩")
print("已保存图片到:", p2)
except Exception as e:
print("保存图片失败:", e)在图片和语音文件都有了之后,我们可以将图片和音频文件合成起来,其中每个图片占据大概多长的时间就看语音的长度了。 比如我们有音频,就可以使用音频时长为主的合并方式,比如下面这个命令:
ffmpeg -y -loop 1 -i "bg.jpg" -i "audio.mp3" -vf "scale=1280:720,setsar=1" -c:v libx264 -preset medium -crf 23 -pix_fmt yuv420p -c:a aac -b:a 128k -shortest "out.mp4"上面的命令意思是: ffmpeg 调用 FFmpeg 程序(多媒体处理工具)。
-y 自动覆盖输出文件(若已存在则不提示,直接覆盖)。
-loop 1 对紧随其后的图片输入启用循环(1 表示循环,0 表示不循环)。用于把单张静态图片当作一条持续的视频流输入。
-i "bg.jpg" 第一个输入文件,背景图片(索引为 input 0)。配合 -loop 可无限生成视频帧。
-i "audio.mp3" 第二个输入文件,音频(索引为 input 1)。ffmpeg 会把音频和视频流合并到输出中(默认映射规则会选择合适的流)。
-vf "scale=1280:720,setsar=1" 视频滤镜(video filter)链:
scale=1280:720:将视频(这里是循环的图片帧)缩放到 1280x720 分辨率。 setsar=1:设置样本长宽比(Sample Aspect Ratio)为 1,保证像素为正方形,避免播放时拉伸。 -c:v libx264 指定视频编码器为 libx264(H.264 编码器),常用于兼容性与体积/质量折中。
-preset medium x264 的 preset,控制编码速度与压缩效率的折中(常见值:ultrafast、superfast、veryfast、faster、fast、medium、slow……)。preset 越快质量/压缩率越低;越慢通常压缩更好但耗时更长。medium 是默认折中值。
-crf 23 CRF(Constant Rate Factor),x264 的质量参数(范围通常 0-51,越小质量越高/文件越大)。23 是常用默认值;想更高质量可用 18-20,想更小体积可以增大到 25+。
-pix_fmt yuv420p 指定像素格式为 yuv420p,确保生成的视频在大多数播放器和网页(尤其 H.264)上兼容播放(某些高色度格式可能不被某些播放器支持)。
-c:a aac 指定音频编码器为 AAC(常用的音频编码格式)。
-b:a 128k 音频比特率设置为 128 kb/s(音质/体积折中)。可根据需要改为 64k、192k 等。
-shortest 输出文件在最先结束的输入流结束时停止写入。常用于“图片循环 + 音频”场景:图片无限循环,但 -shortest 会让输出在音频播放结束时终止,从而使视频长度等于音频长度。
"out.mp4" 输出文件名(MP4 容器),包含编码后的视频与音频流。
看到这里,我觉得你已经完全掌握了如何通过使用大模型自动化视频生成的完整流程!
- 硅基流动API:获取免费API Key
- FFmpeg官网:下载与文档
- 项目源码:欢迎 Star 和贡献代码
本项目基于开源许可证发布,详见 LICENSE 文件。