[REQ] Delossifier function #356
Replies: 19 comments 62 replies
-
|
Thanks for the idea. I also see some MP3 restoration models listed here: https://github.com/ZFTurbo/Music-Source-Separation-Training/blob/main/docs/pretrained_models.md#single-stem-models As always, it would be very helpful to get some help from the community to evaluate & validate quality of the projects & available pre-trained models. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the hint and happy new year, @RyanMetcalfeInt8 ! Just added Apollo by @JusperLee under AUDIO \ AI-based \ Restorers:
Anyway I honestly didn't understand exactly how it can work since it relies on music separation nnet, even if:
Hope that active nnet-based "audio restoration" projects' devs (such as @asjad895, @AakashRevankar, @matthewmcq, @shaws34, @bkraad47 and @kroll-software of course) will join this discussion too. If can help I'll try to engage Hydrogenaudio's experts again for qualitative evaluation of restorers' outputs. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you for your attention, our publicly available pre-trained model for this method was trained using only open source data. If you guys train with more data, you are able to get better generalization performance. |
Beta Was this translation helpful? Give feedback.
-
|
If want to try fast: https://huggingface.co/spaces/patriotyk/Apollo |
Beta Was this translation helpful? Give feedback.
-
|
@yoongi43 - the Exploiting Time-Frequency Conformers for Music Audio Enhancement author - just noticed about this discussion. |
Beta Was this translation helpful? Give feedback.
-
|
Just discovered this interesting Audio Super Resolution implementation by @jakeoneijk: Abstract from the relative paper:
Hope that inspires ! |
Beta Was this translation helpful? Give feedback.
-
|
Well, listening the examples FlashSR seems better of Audio SR about quality. |
Beta Was this translation helpful? Give feedback.
-
|
Very interesting! |
Beta Was this translation helpful? Give feedback.
-
|
I think, you all doing a great job pushing this idea further. |
Beta Was this translation helpful? Give feedback.
-
|
Have someone objectively compared quality of these models (AudioSR, Apollo, FlashSR and maybe something else)? I like both Apollo and FlashSR in terms of quality) |
Beta Was this translation helpful? Give feedback.
-
|
hydrogenaudio's listening test is needed for, IMHO. |
Beta Was this translation helpful? Give feedback.
-
|
Bump. Seems that @JusperLee's Apollo is gaining results (and needs optimization on Intel-*PUs)...
|

Beta Was this translation helpful? Give feedback.
-
|
Hi all! I apologize for not contributing much to the thread until now, but I just wrapped up my thesis which I feel has some fairly profound implications for audio restoration. Unfortunately, I did not get the change to directly integrate any of these algorithms into a DL pipeline, but I feel y'all are the type of people who would know what to do with it better than me. TLDR is I developed an optimized algorithm to convert from a DFT spectrum into the set of constituent "true" continuous components with more or less arbitrarily good accuracy. In my thesis I used it to "clean" an STFT and for a pretty novel resampling approach. Code is available here. If you're at all curious to read the actual thesis to get a better idea of the theoretical foundations or to see the results visualized, the pdf is in the folder titled "thesis." Have a great weekend! |
Beta Was this translation helpful? Give feedback.
-
|
Bump. Just discovered @rajasekarnp1's / @31jay's Neural Audio Upscaler project: models aren't present (but the Project Summary claims "Voice, Music, Ambient and General") and I don't exactly understand inference platform they relies on, but the approach seems interesting. |
Beta Was this translation helpful? Give feedback.
-
|
Ok, with the help of GH-Copilot I've finally "ported" the latest @kroll-software's AudioDelossifier (and, of course, converted provided models) to run - locally - exploiting OpenVINO. https://github.com/MarcoRavich/OV-AudioDelossifier#readme It's still pretty raw of course, but it seems to infere without errors. I'm waiting for your feedbacks and suggestions to improve it further. |
Beta Was this translation helpful? Give feedback.
-
|
Strange, I downloaded your fork and installed the requirements.txt, now with your latest commit I get this: Can you check that the one you use locally is the same as the fork? |
Beta Was this translation helpful? Give feedback.
-
|
Remember that |
Beta Was this translation helpful? Give feedback.
-
|
Ok but it's the same thing, I corrected the error like this: def read_audiofile(filename, target_sr=44100, channels=2):
# ...
data, samplerate = sf.read(filename, dtype='float32', always_2d=True)
# ...
return data, samplerateand deleted af.write_audiofile_wav(output_audio, out_fname) #dtype=np.float32so: but:
|

Beta Was this translation helpful? Give feedback.
-
|
32bit fp audio output - using
Anyway, as claimed above, you have to generate a null mix (in Audacity select one track and perform Effect -> Special -> Invert, then select both and perform Tracks -> Mix -> Mix and Render to New Track) to be able to get the differences between lossy source and delossifyed result:
|


Beta Was this translation helpful? Give feedback.
-
|
Okok, sorry for my misunderstanding :) |
Beta Was this translation helpful? Give feedback.
-
|
I really appreciate all your efforts and progress. Some ideas for improvements:
Detlef |
Beta Was this translation helpful? Give feedback.
-
|
Bump. Thanks to @jarredou's Apollo-Colab-Inference repo I've discovered the Universal model for any lossy files by Lew bringed by @deton24. I've failed to convert it to ONNX format, anyway I'm trying to inference with it as is. Any suggestion @RyanMetcalfeInt8 ? |
Beta Was this translation helpful? Give feedback.
-
|
@RyanMetcalfeInt8: I wonder if @matthewmcq's models (aka upscalemp3) will be included too in the next version... ...anyway, with this huge prolification of supported models, something like ChaiNNer's approach will be needed at some point IMHO:
|
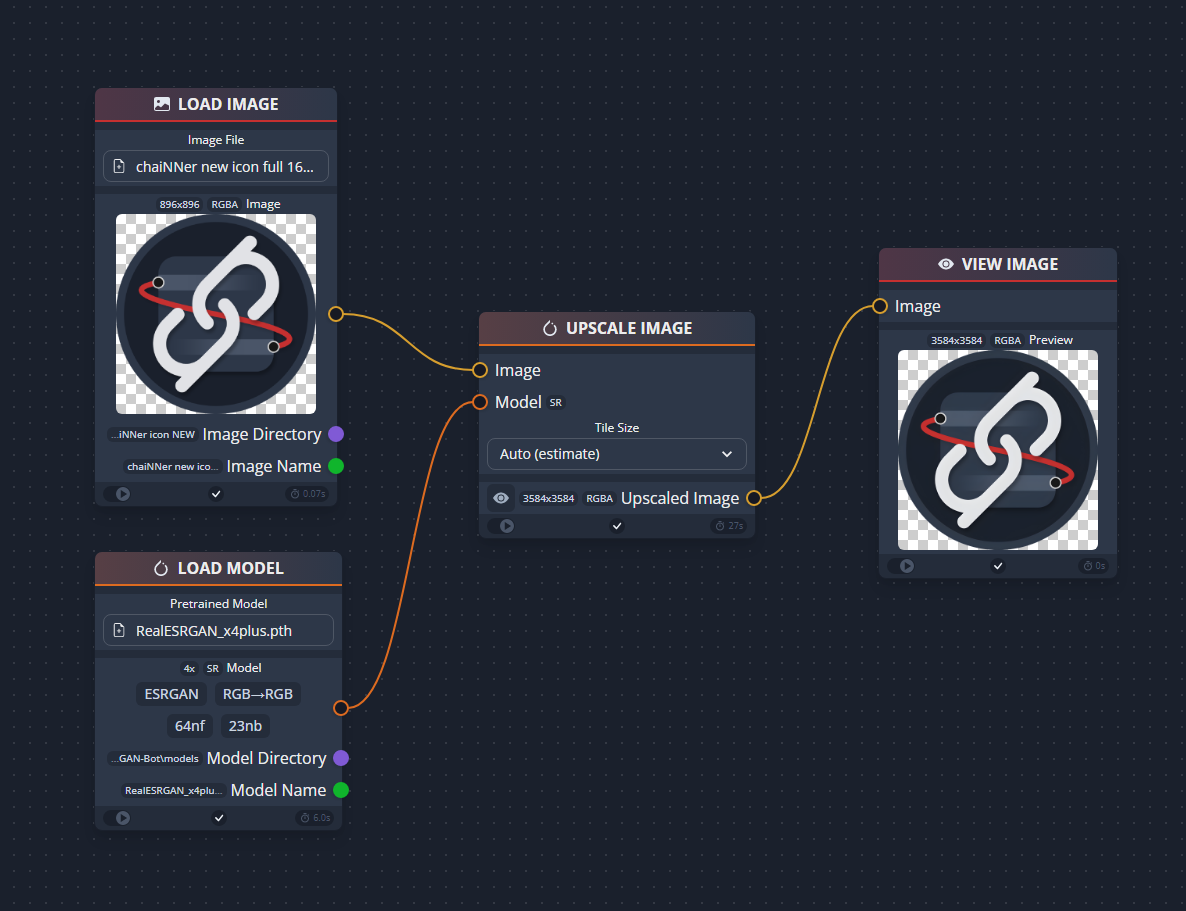
Beta Was this translation helpful? Give feedback.
-
|
Hi @MarcoRavich -- I think the set of new models / features for next release is pretty much locked in at this point, as I'd like to get it out as soon as possible and is already taking me much longer than I wanted. Regarding this kind of DAG UI -- I guess we can address it when the time comes. If it ever happens, it would need to be with AU4. |
Beta Was this translation helpful? Give feedback.
-
I still can't wait for ! |
Beta Was this translation helpful? Give feedback.
-
|
Waiting (impatiently) for the next release, thanks to @olilarkin I've discovered this cool Node-based GUI for CDP by @j-p-higgins that, as cited ChaiNNer, could inspire:
(just a note) |
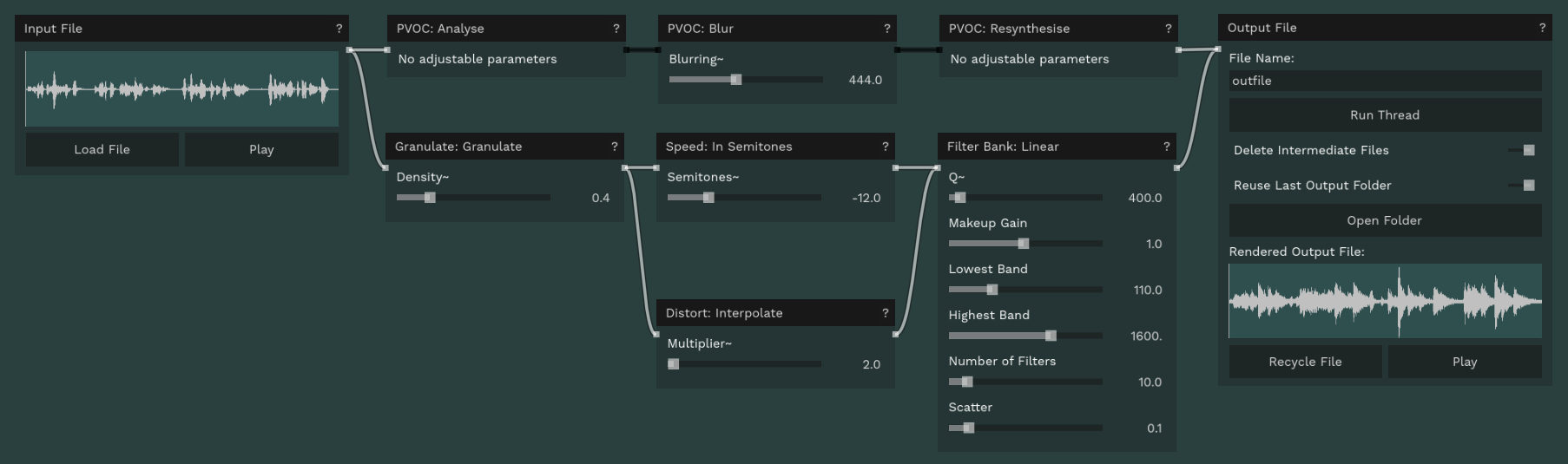
Beta Was this translation helpful? Give feedback.
-
Hey @jarredou -- Sorry, I think I missed this one, but yes absolutely -- this one is being targeted for the next release. And maybe just a quick update / outlook on next release -- It's coming along, apologies it's taking me much longer than I anticipated. Hoping to get it out in a month or so. Note that, all development is happening 'in the open' though, on this branch: https://github.com/intel/openvino-plugins-ai-audacity/tree/next Nothing really stopping you from building it / trying it out yourself: I finally was able to post HuggingFace spaces for most of the new models (e.g. https://huggingface.co/Intel/drumsep_mdx23c_jarredou_openvino) , and so they are installable via the new model manager UI: (I still need to add residual output for that 6th stem, hence the screenshot.. but I'll do that next couple of days) The model card info is generated from a set of .md's here: https://github.com/intel/openvino-plugins-ai-audacity/tree/next/model_cards Very happy to accept any tweaks / info that you think is missing from those. |

Beta Was this translation helpful? Give feedback.
-
|
Sorry for maybe stupid questions but is it possible to use this on a Nvidia gpu (on a cpu it's soo long) and is there any better delossifier in terms of quality ? |
Beta Was this translation helpful? Give feedback.
-
|
You're asking about our AI plugins in general? If so, then unfortunately not, OpenVINO doesn't have a 'backed' that supports NVidia (CUDA). |
Beta Was this translation helpful? Give feedback.
-
Ehm, did you notice we're into @intel repositories ?
Well Apollo maybe, but not for OpenVINO at the moment. Anyway, if you own an NVIDIA GPU, why don't you train models yourself (and share please) ?!? |
Beta Was this translation helpful? Give feedback.
-
|
I'm sorry, but no. I'll write back if they come up.
pon., 7 lip 2025, 17:21 użytkownik Ryan Metcalfe ***@***.***>
napisał:
… Hi @deton24 <https://github.com/deton24> -- Any chance you heard back
from Lew? I've been occasionally checking your GDoc (which is amazing btw),
but didn't see any info there. I guess chances are, you didn't hear
anything -- but I figured I'd check :)
I just really want to release this model with our plugins, as it's pretty
amazing..
—
Reply to this email directly, view it on GitHub
<#356 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AIJ3EHGBPMKOMM5I23NNJXT3HKGBDAVCNFSM6AAAAABUPP3MJCVHI2DSMVQWIX3LMV43URDJONRXK43TNFXW4Q3PNVWWK3TUHMYTGNRYGU2TGOI>
.
You are receiving this because you were mentioned.Message ID:
<intel/openvino-plugins-ai-audacity/repo-discussions/356/comments/13685539
@github.com>
|
Beta Was this translation helpful? Give feedback.
-
|
[BREAKING] Shut up, the enemy is listening! 😄 A2SB: Audio-to-Audio Schrodinger Bridges (by Nvidia) implementation released:
Git: https://github.com/NVIDIA/diffusion-audio-restoration#readme |
Beta Was this translation helpful? Give feedback.
-
|
Sorry, I forgot to mention the other contenders cited in the A2SB's test (which are interesting too):
Hope that inspires ! |
Beta Was this translation helpful? Give feedback.
-
|
Thank you @MarcoRavich! I'm always a little delayed to respond these days but I do love all of this stuff that you share. I am inspired -- Keep it coming! |
Beta Was this translation helpful? Give feedback.
-
|
End of Aug25 bump Here's Audio Restoration Studio by @duchannes19, an interesting Gradio-GUI for comparing restoration models: |
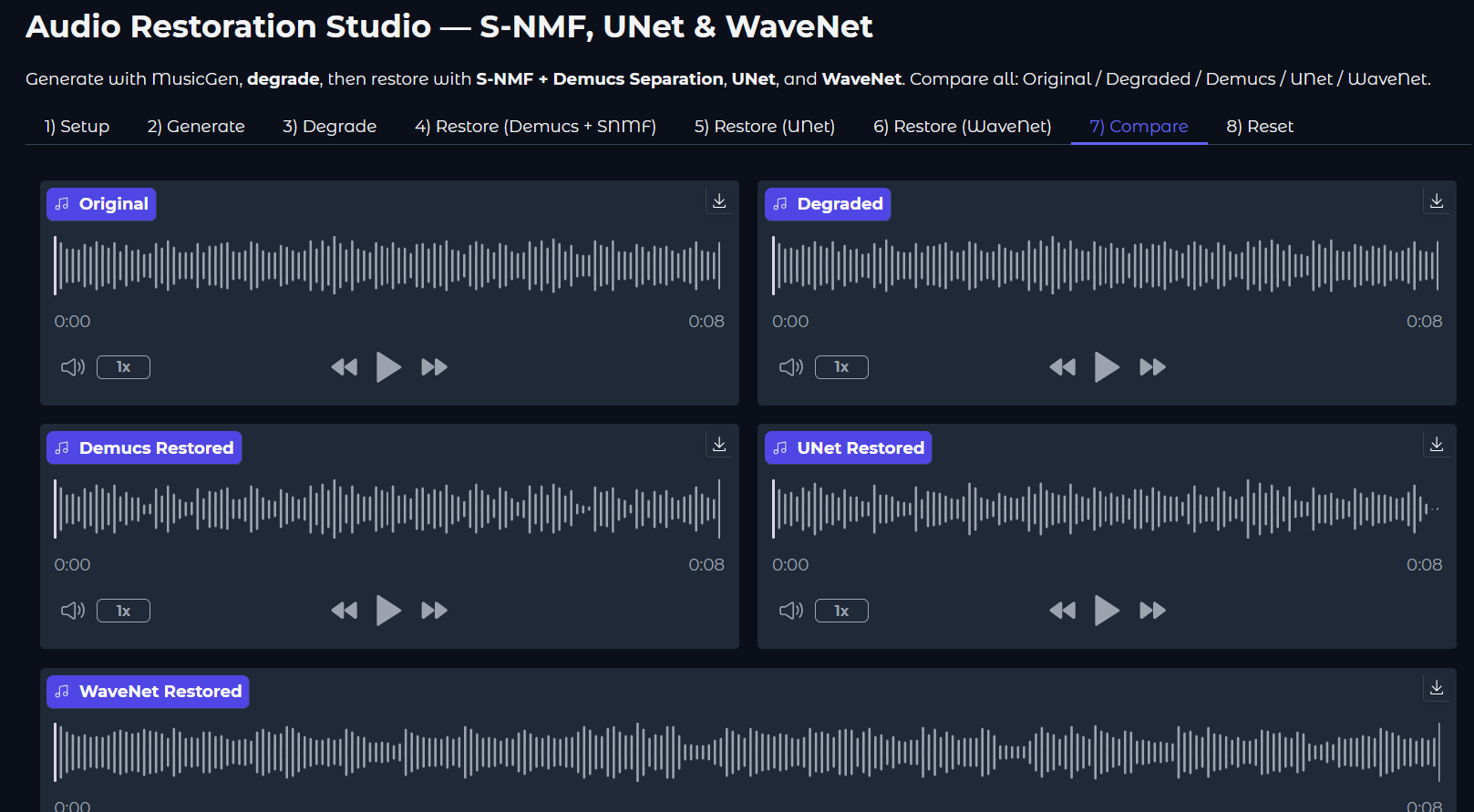
Beta Was this translation helpful? Give feedback.
-
|
It's maybe barely OT, but I've just updated the HyMPS project \ AUDIO \ AI-based \ Enhancers page resources collection with direct links to available pretrained models (in the "Models" column of course): enjoy and let me know how to improve it. |
Beta Was this translation helpful? Give feedback.
-
|
Incredibly impressive work with HyMPS. Still, it would be nice to have the
best stuff sorted somehow by currently the best solutions, or with more
info on what to actually use, then just have a massive list with no clue
where to start. Look around here. There's some stuff lucking on your list
from what I've checked a month or so ago:
https://docs.google.com/document/d/1GLWvwNG5Ity2OpTe_HARHQxgwYuoosseYcxpzVjL_wY/edit?tab=t.0#heading=h.i7mm2bj53u07
śr., 10 wrz 2025 o 12:29 Marco Ravich ***@***.***> napisał(a):
… It's maybe barely OT, but I've just updated the HyMPS project
<https://forart.it/HyMPS> \ AUDIO <https://github.com/FORARTfe/HyMPS#-> \
AI-based
<https://github.com/FORARTfe/HyMPS/blob/main/Audio/AI-based.md#--> \ Enhancers
page
<https://github.com/FORARTfe/HyMPS/blob/main/Audio/AI-Enhancing.md#--->
resources collection with direct links to available pretrained models (in
the "Models" column of course): enjoy and let me know how to improve it.
—
Reply to this email directly, view it on GitHub
<#356 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AIJ3EHHQ7YGXUWSXGXGQK633R74R3AVCNFSM6AAAAABUPP3MJCVHI2DSMVQWIX3LMV43URDJONRXK43TNFXW4Q3PNVWWK3TUHMYTIMZWGEZTSMY>
.
You are receiving this because you were mentioned.Message ID:
<intel/openvino-plugins-ai-audacity/repo-discussions/356/comments/14361393
@github.com>
|
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Hi there,
after the recent cool super resolution feature add, it would be great to have a tool able to "delossify" - as far as possible - compressed audio.
@kroll-software has recently updated their Audio Delossifier and a brunch of pre-trained models (for mp3 delossification) are provided too.
Last but not least, I've just created a simple script to inference on Colab: kroll-software/AudioDelossifier#5 (comment)
Hope that inspires !
Beta Was this translation helpful? Give feedback.
All reactions