Releases: huggingface/transformers
v4.56: Dino v3, X-Codec, Ovis 2, MetaCLIP 2, Florence 2, SAM 2, Kosmos 2.5, HunYuan, GLMV-4.5
New model additions
Dino v3
DINOv3 is a family of versatile vision foundation models that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models.
You can find all the original DINOv3 checkpoints under the DINOv3 collection.

X-Codec
he X-Codec model was proposed in Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model by Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qifeng Liu, Yike Guo, Wei Xue
The X-Codec model is a neural audio codec that integrates semantic information from self-supervised models (e.g., HuBERT) alongside traditional acoustic information. This enables :
- Music continuation : Better modeling of musical semantics yields more coherent continuations.
- Text-to-Sound Synthesis : X-Codec captures semantic alignment between text prompts and generated audio.
- Semantic aware audio tokenization: X-Codec is used as an audio tokenizer in the YuE lyrics to song generation model.

- Add X-Codec model by @Manalelaidouni in #38248
Ovis 2
The Ovis2 is an updated version of the Ovis model developed by the AIDC-AI team at Alibaba International Digital Commerce Group.
Ovis2 is the latest advancement in multi-modal large language models (MLLMs), succeeding Ovis1.6. It retains the architectural design of the Ovis series, which focuses on aligning visual and textual embeddings, and introduces major improvements in data curation and training methods.
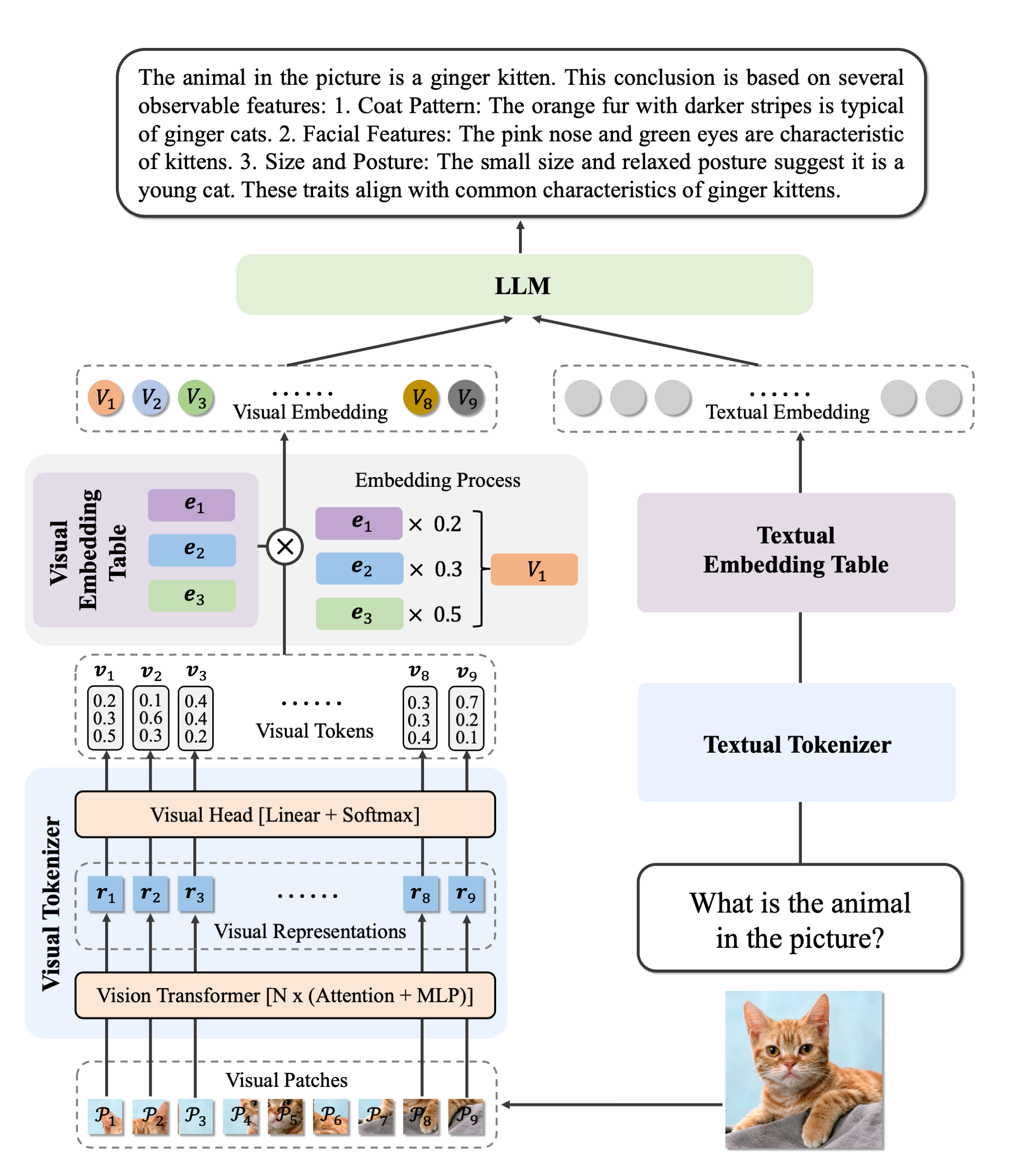
- Add Ovis2 model and processor implementation by @thisisiron in #37088
MetaCLIP 2
MetaCLIP 2 is a replication of the original CLIP model trained on 300+ languages. It achieves state-of-the-art (SOTA) results on multilingual benchmarks (e.g., XM3600, CVQA, Babel‑ImageNet), surpassing previous SOTA such as mSigLIP and SigLIP‑2. The authors show that English and non-English worlds can mutually benefit and elevate each other.

- Add MetaCLIP 2 by @NielsRogge in #39826
Florence 2
Florence-2 is an advanced vision foundation model that uses a prompt-based approach to handle a wide range of vision and vision-language tasks. Florence-2 can interpret simple text prompts to perform tasks like captioning, object detection, and segmentation. It leverages the FLD-5B dataset, containing 5.4 billion annotations across 126 million images, to master multi-task learning. The model's sequence-to-sequence architecture enables it to excel in both zero-shot and fine-tuned settings, proving to be a competitive vision foundation model.

- Add support for Florence-2 by @ducviet00 in #38188
SAM 2
SAM2 (Segment Anything Model 2) was proposed in Segment Anything in Images and Videos by Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer.
The model can be used to predict segmentation masks of any object of interest given an input image or video, and input points or bounding boxes.

- Add Segment Anything 2 (SAM2) by @SangbumChoi in #32317
Kosmos 2.5
The Kosmos-2.5 model was proposed in KOSMOS-2.5: A Multimodal Literate Model by Microsoft.
The abstract from the paper is the following:
We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.

HunYuan

More information at release 🤗
Seed OSS

More information at release 🤗
- Adding ByteDance Seed Seed-OSS by @Fazziekey in #40272
GLM-4.5V
More information at release 🤗
- GLM-4.5V Model Support by @zRzRzRzRzRzRzR in #39805
Cache
Beyond a large refactor of the caching system in Transformers, making it much more practical and general, models using sliding window attention/chunk attention do not waste memory anymore when caching past states. It was allowed most notable by:
- New DynamicSlidingWindowLayer & associated Cache by @Cyrilvallez in #40039
See the following improvements on memory usage for Mistral (using only sliding layers) and GPT-OSS (1 out of 2 layers is sliding) respectively:


Beyond memory usage, it will also improve generation/forward speed by a large margin for large contexts, as only necessary states are passed to the attention computation, which is very sensitive to the sequence length.
Quantization
MXFP4
Since the GPT-OSS release which introduced the MXPF4 quantization type, several improvements have been made to the support, which should now stabilize.
- Fix MXFP4 quantizer validation to allow CPU inference with dequantize option by @returnL in #39953
- Enable gpt-oss mxfp4 on older hardware (sm75+) by @matthewdouglas in #39940
- Fix typo and improve GPU kernel check error message in MXFP4 quantization by @akintunero in #40349)
- Default to dequantize if cpu in device_map for mxfp4 by @MekkCyber in #39993
- Fix GPT-OSS
swiglu_limitnot passed in for MXFP4 by @danielhanchen in #40197 - [
Mxfp4] Add a way to save with a quantization method by @ArthurZucker in #40176
New standard
Now that we deprecated tensorflow and jax, we felt that torch_dtype was not only misaligned with torch, but was redundant and hard to remember. For this reason, we switched to a much more standard dtype argument!
⚠️ ⚠️ Use dtype instead of torch_dtype everywhere! by @Cyrilvallez in #39782
torch_dtype will still be a valid usage for as long as needed to ensure a smooth transition, but new code should use dtype, and we encourage you to update older code as well!
Breaking changes
The following commits are breaking changes in workflows that were either buggy or not working as expected.
Saner hub-defaults for hybrid cache implementation
On models where the hub checkpoint specifies cache_implementation="hybrid" (static sliding window hybrid cache), UNSETS this value. This will make the model use the dynamic sliding window layers by default.
This default meant that there were widespread super slow 1st generate calls on models with hybrid caches, which should nol onger be the case.
Sine positional embeddings for MaskFormer & LRU cache
Cache the computation of sine positional embeddings for MaskFormer; results in a 6% performance improvement.
- 🚨 Use lru_cache for sine pos embeddings MaskFormer by @yonigozlan in #40007
Explicit cache initialization
Adds explicit cache initialization to prepare for the deprecation of the from_legacy_cache utility.
- 🚨 Always return Cache objects in modelings (to align with generate) by @manueldeprada...
Contributors
Assets 2
Patch v4.55.4
Patch release v4.55.3
Patch release 4.55.3
Focused on stabilizing FlashAttention-2 on Ascend NPU, improving FSDP behavior for generic-task models, fixing MXFP4 integration for GPT-OSS
Bug Fixes & Improvements
- FlashAttention-2 / Ascend NPU – Fix “unavailable” runtime error (#40151) by @FightingZhen
- FlashAttention kwargs – Revert FA kwargs preparation to resolve regression (#40161) by @Cyrilvallez
- FSDP (generic-task models) – Fix sharding/runtime issues (#40191) by @Cyrilvallez
- GPT-OSS / MXFP4 – Ensure swiglu_limit is correctly passed through (#40197) by @danielhanchen
- Mamba – Fix cache handling to prevent stale/incorrect state (#40203) by @manueldeprada
- Misc – Minor follow-up fix addressing #40262 by @ArthurZucker
Contributors
Assets 2
Patch release 4.55.2: for FA2 users!
Patch release 4.55.2!
only affects FA2 generations!
😢 Well sorry everyone, sometimes shit can happen...
4.55.1 was broken because of 🥁 git merge conflict.
I cherry-picked #40002 without having #40029 , thus from ..modeling_flash_attention_utils import prepare_fa_kwargs_from_position_ids is missing, and since this is a slow test, nothing caught it.
Will work to remediate and write the post-mortem when yanking the release.
Patch release 4.55.1
Patch release 4.55.1:
Mostly focused around stabalizing the Mxfp4 for GPTOSS model!
Bug Fixes & Improvements
- Idefics2, Idefics3, SmolVLM – Fix tensor device issue (#39975) by @qgallouedec
- Merge conflicts – Fix merge conflicts from previous changes by @vasqu
- MXFP4 / CPU device_map – Default to dequantize when CPU is in device_map (#39993) by @MekkCyber
- GPT Big Code – Fix attention scaling (#40041) by @vasqu
- Windows compatibility – Resolve Triton version check compatibility (#39986) by @Tsumugii24 @MekkCyber
- Gemma3n model – Add missing None default values for get_placeholder_mask (#39991, #40024) by @Znerual
- Fuyu model – Fix broken image inference (#39915) by @Isotr0py
- PerceptionLM – Fix missing video inputs (#39971) by @shuminghu
- Idefics – Fix device mismatch (#39981) by @zucchini-nlp
- Triton kernels – Remove triton_kernels dependency in favor of included kernels (#39926) by @SunMarc
- GPT-OSS MXFP4 – Enable on older hardware (sm75+) (#39940) by @matthewdouglas @SunMarc
- MXFP4 quantizer – Allow CPU inference with dequantize option (#39953) by @returnL
CI & Build
- CI stability – Post-GPT-OSS fixes for green CI (#39929) by @gante @LysandreJik
Contributors
Assets 2
GLM-4.5V preview based on 4.55.0
GLM-4.5V preview based on 4.55.0
New model added by the Z.ai team to transformers!
GLM-4.5V is a new multimodal reasoning model based on GLM-4.5-Air, which has 106B total and 12B active parameters.
It's performant across 42 benchmarks across various categories:
- Image reasoning (scene understanding, complex multi-image analysis, spatial recognition)
- Video understanding (long video segmentation and event recognition)
- GUI tasks (screen reading, icon recognition, desktop operation assistance)
- Complex chart & long document parsing (research report analysis, information extraction)
- Grounding (precise visual element localization)

To use, install transformers release branch.
pip install transformers-v4.55.0-GLM-4.5V-previewThen you can run:
from transformers import AutoProcessor, Glm4vMoeForConditionalGeneration
import torch
MODEL_PATH = "zai-org/GLM-4.5V"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png"
},
{
"type": "text",
"text": "describe this image"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH)
model = Glm4vMoeForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype="auto",
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
inputs.pop("token_type_ids", None)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)v4.55.0: New openai GPT OSS model!
Welcome GPT OSS, the new open-source model family from OpenAI!

For more detailed information about this model, we recommend reading the following blogpost: https://huggingface.co/blog/welcome-openai-gpt-oss
GPT OSS is a hugely anticipated open-weights release by OpenAI, designed for powerful reasoning, agentic tasks, and versatile developer use cases. It comprises two models: a big one with 117B parameters (gpt-oss-120b), and a smaller one with 21B parameters (gpt-oss-20b). Both are mixture-of-experts (MoEs) and use a 4-bit quantization scheme (MXFP4), enabling fast inference (thanks to fewer active parameters, see details below) while keeping resource usage low. The large model fits on a single H100 GPU, while the small one runs within 16GB of memory and is perfect for consumer hardware and on-device applications.
Overview of Capabilities and Architecture
- 21B and 117B total parameters, with 3.6B and 5.1B active parameters, respectively.
- 4-bit quantization scheme using mxfp4 format. Only applied on the MoE weights. As stated, the 120B fits in a single 80 GB GPU and the 20B fits in a single 16GB GPU.
- Reasoning, text-only models; with chain-of-thought and adjustable reasoning effort levels.
- Instruction following and tool use support.
- Inference implementations using transformers, vLLM, llama.cpp, and ollama.
- Responses API is recommended for inference.
- License: Apache 2.0, with a small complementary use policy.
Architecture
- Token-choice MoE with SwiGLU activations.
- When calculating the MoE weights, a softmax is taken over selected experts (softmax-after-topk).
- Each attention layer uses RoPE with 128K context.
- Alternate attention layers: full-context, and sliding 128-token window.
- Attention layers use a learned attention sink per-head, where the denominator of the softmax has an additional additive value.
- It uses the same tokenizer as GPT-4o and other OpenAI API models.
- Some new tokens have been incorporated to enable compatibility with the Responses API.
The following snippet shows simple inference with the 20B model. It runs on 16 GB GPUs when using mxfp4, or ~48 GB in bfloat16.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "openai/gpt-oss-20b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype="auto",
)
messages = [
{"role": "user", "content": "How many rs are in the word 'strawberry'?"},
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to(model.device)
generated = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(generated[0][inputs["input_ids"].shape[-1]:]))Flash Attention 3
The models use attention sinks, a technique the vLLM team made compatible with Flash Attention 3. We have packaged and integrated their optimized kernel in kernels-community/vllm-flash-attn3. At the time of writing, this super-fast kernel has been tested on Hopper cards with PyTorch 2.7 and 2.8. We expect increased coverage in the coming days. If you run the models on Hopper cards (for example, H100 or H200), you need to pip install –upgrade kernels and add the following line to your snippet:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "openai/gpt-oss-20b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype="auto",
+ # Flash Attention with Sinks
+ attn_implementation="kernels-community/vllm-flash-attn3",
)
messages = [
{"role": "user", "content": "How many rs are in the word 'strawberry'?"},
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to(model.device)
generated = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(generated[0][inputs["input_ids"].shape[-1]:]))Even though the 120B model fits on a single H100 GPU (using mxfp4), you can also run it easily on multiple GPUs using accelerate or torchrun. Transformers provides a default parallelization plan, and you can leverage optimized attention kernels as well. The following snippet can be run with torchrun --nproc_per_node=4 generate.py on a system with 4 GPUs:
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.distributed import DistributedConfig
import torch
model_path = "openai/gpt-oss-120b"
tokenizer = AutoTokenizer.from_pretrained(model_path, padding_side="left")
device_map = {
"tp_plan": "auto", # Enable Tensor Parallelism
}
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype="auto",
attn_implementation="kernels-community/vllm-flash-attn3",
**device_map,
)
messages = [
{"role": "user", "content": "Explain how expert parallelism works in large language models."}
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=1000)
# Decode and print
response = tokenizer.decode(outputs[0])
print("Model response:", response.split("<|channel|>final<|message|>")[-1].strip())Other optimizations
If you have a Hopper GPU or better, we recommend you use mxfp4 for the reasons explained above. If you can additionally use Flash Attention 3, then by all means do enable it!
Tip
If your GPU is not compatible with mxfp4, then we recommend you use MegaBlocks MoE kernels for a nice speed bump. To do so, you just need to adjust your inference code like this:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "openai/gpt-oss-20b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype="auto",
+ # Optimize MoE layers with downloadable MegaBlocksMoeMLP
+ use_kernels=True,
)
messages = [
{"role": "user", "content": "How many rs are in the word 'strawberry'?"},
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True,
).to(model.device)
generated = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(generated[0][inputs["input_ids"].shape[-1]:]))Tip
MegaBlocks optimized MoE kernels require the model to run on bfloat16, so memory consumption will be higher than running on mxfp4. We recommend you use mxfp4 if you can, otherwise opt in to MegaBlocks via use_kernels=True.
transformers serve
You can use transformers serve to experiment locally with the models, without any other dependencies. You can launch the server with just:
transformers serve
To which you can send requests using the Responses API.
# responses API
curl -X POST http://localhost:8000/v1/responses \
-H "Content-Type: application/json" \
-d '{"input": [{"role": "system", "content": "hello"}], "temperature": 1.0, "stream": true, "model": "openai/gpt-oss-120b"}'
You can also send requests using the standard Completions API:
# completions API
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"messages": [{"role": "system", "content": "hello"}], "temperature": 1.0, "max_tokens": 1000, "stream": true, "model": "openai/gpt-oss-120b"}'
Command A Vision

Command A Vision is a state-of-the-art multimodal model designed to seamlessly integrate visual and textual information for a wide range of applications. By combining advanced computer vision techniques with natural language processing capabilities, Command A Vision enables users to analyze, understand, and generate insights from both visual and textual data.
The model excels at tasks including image captioning, visual question answering, document understanding, and chart understanding. This makes it a versatile tool for AI practitioners. Its ability to process complex visual and textual inputs makes it useful in settings where text-only representations are imprecise or unavailable, like real-world image understanding and graphics-heavy document processing.
Command A Vision is built upon a robust architecture that leverages the latest advancements in VLMs. It's highly performant and efficient, even when dealing with large-scale datasets. The model's flexibility makes it suitable for a wide range of use cases, from content moderation and image search to medical imaging analysis and robotics.
- [Model] Cohere2 Vision by @zucchini-nlp in #39810
MM Grounding DINO

MM Grounding DINO model was proposed in An Open and Comprehensive Pipeline for Unified Object Grounding and Detection by Xiangyu Zhao, Yicheng Chen, Shilin Xu, Xiangtai Li, Xinjiang Wang, Yining Li, Haian Huang>.
MM Grounding DINO improves upon the [G...
Contributors
Assets 2
Patch release 4.54.1
Patch release 4.54.1
We had quite a lot of bugs that got through! Release was a bit rushed, sorry everyone! 🤗
Mostly cache fixes, as we now have layered cache, and fixed to distributed.
- Fix Cache.max_cache_len max value for Hybrid models, @manueldeprada, @Cyrilvallez, #39737
- [modenbert] fix regression, @zucchini-nlp, #39750
- Fix version issue in modeling_utils.py, @Cyrilvallez, #39759
- Fix GPT2 with cross attention, @zucchini-nlp, #39754
- Fix mamba regression, @manueldeprada, #39728
- Fix: add back base model plan, @S1ro1, #39733
- fix cache inheritance, #39748
- Fix cache-related tests, @zucchini-nlp, #39676
- Fix Layer device placement in Caches, @Cyrilvallez, #39732
- PATCH: add back n-dim device-mesh + fix tp trainer saving, @S1ro1, @SunMarc, #39693
- fix missing model._tp_size from ep refactor, @winglian, #39688
Contributors
Assets 2
v4.54.0: Kernels, Transformers Serve, Ernie, Voxtral, LFM2, DeepSeek v2, ModernBERT Decoder...
Important news!
In order to become the source of truth, we recognize that we need to address two common and long-heard critiques about transformers:
transformersis bloatedtransformersis slow
Our team has focused on improving both aspects, and we are now ready to announce this.
The modeling files for the standard Llama models are down to 500 LOC and should be much more readable, keeping just the core of the modeling and hiding the "powerful transformers features."

The MoEs are getting some kernel magic, enabling the use of the efficient megablocks kernels, setting a good precedent to allow the community to leverage any of the most powerful kernels developed for quantization as well!
It should also be much more convenient to use with any attention implementation you want. This opens the door to some optimizations such as leveraging flash-attention on Metal (MPS Torch backend).

This is but the tip of the iceberg: with the work on kernels that we're heavily pushing forward, expect speed-ups on several backends in the coming months!!
This release also includes the first steps to enabling efficient distributed training natively in transformers. Loading a 100B model takes ~3 seconds on our cluster — we hope this will be the norm for everyone! We are working on distributed checkpointing as well, and want to make sure our API can be easily used for any type of parallelism.
We want the community to benefit from all of the advances, and as always, include all hardware and platforms! We believe the kernels library will give the tools to optimize everything, making a big difference for the industry!
New models
Ernie 4.5
The Ernie 4.5 model was released in the Ernie 4.5 Model Family release by baidu.
This family of models contains multiple different architectures and model sizes. This model in specific targets the base text
model without mixture of experts (moe) with 0.3B parameters in total. It uses the standard Llama at its core.
Other models from the family can be found at Ernie 4.5 MoE.

Voxtral
Voxtral is an upgrade of Ministral 3B and Mistral Small 3B, extending its language capabilities with audio input support. It is designed to handle tasks such as speech transcription, translation, and audio understanding.
You can read more in Mistral's realease blog post.
The model is available in two checkpoints:
Key Features
Voxtral builds on Ministral-3B by adding audio processing capabilities:
- Transcription mode: Includes a dedicated mode for speech transcription. By default, Voxtral detects the spoken language and transcribes it accordingly.
- Long-form context: With a 32k token context window, Voxtral can process up to 30 minutes of audio for transcription or 40 minutes for broader audio understanding.
- Integrated Q&A and summarization: Supports querying audio directly and producing structured summaries without relying on separate ASR and language models.
- Multilingual support: Automatically detects language and performs well across several widely spoken languages, including English, Spanish, French, Portuguese, Hindi, German, Dutch, and Italian.
- Function calling via voice: Can trigger functions or workflows directly from spoken input based on detected user intent.
- Text capabilities: Maintains the strong text processing performance of its Ministral-3B foundation.
LFM2
LFM2 represents a new generation of Liquid Foundation Models developed by Liquid AI, specifically designed for edge AI and on-device deployment.
The models are available in three sizes (350M, 700M, and 1.2B parameters) and are engineered to run efficiently on CPU, GPU, and NPU hardware, making them particularly well-suited for applications requiring low latency, offline operation, and privacy.
- LFM2 by @paulpak58 in #39340
DeepSeek v2
The DeepSeek-V2 model was proposed in DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model by DeepSeek-AI Team.
The model uses Multi-head Latent Attention (MLA) and DeepSeekMoE architectures for efficient inference and cost-effective training. It employs an auxiliary-loss-free strategy for load balancing and multi-token prediction training objective. The model can be used for various language tasks after being pre-trained on 14.8 trillion tokens and going through Supervised Fine-Tuning and Reinforcement Learning stages.
- Add DeepSeek V2 Model into Transformers by @VladOS95-cyber in #36400
ModernBERT Decoder models
ModernBERT Decoder is the same architecture as ModernBERT but trained from scratch with a causal language modeling (CLM) objective. This allows for using the same architecture for comparing encoders and decoders. This is the decoder architecture implementation of ModernBERT, designed for autoregressive text generation tasks.
Like the encoder version, ModernBERT Decoder incorporates modern architectural improvements such as rotary positional embeddings to support sequences of up to 8192 tokens, unpadding to avoid wasting compute on padding tokens, GeGLU layers, and alternating attention patterns. However, it uses causal (unidirectional) attention to enable autoregressive generation.
EoMT
The Encoder-only Mask Transformer (EoMT) model was introduced in the CVPR 2025 Highlight Paper Your ViT is Secretly an Image Segmentation Model by Tommie Kerssies, Niccolò Cavagnero, Alexander Hermans, Narges Norouzi, Giuseppe Averta, Bastian Leibe, Gijs Dubbelman, and Daan de Geus.
EoMT reveals Vision Transformers can perform image segmentation efficiently without task-specific components.

- ✨ Add EoMT Model || 🚨 Fix Mask2Former loss calculation by @yaswanth19 in #37610
Doge
Doge is a series of small language models based on the Doge architecture, aiming to combine the advantages of state-space and self-attention algorithms, calculate dynamic masks from cached value states using the zero-order hold method, and solve the problem of existing mainstream language models getting lost in context. It uses the wsd_scheduler scheduler to pre-train on the smollm-corpus, and can continue training on new datasets or add sparse activation feedforward networks from stable stage checkpoints.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/refs%2Fpr%2F426/transformers/model_doc/doge_architecture.png" alt="drawing" width="600"
{kind=link}
- Add Doge model by @LoserCheems in #35891
AIM v2
The AIMv2 model was proposed in Multimodal Autoregressive Pre-training of Large Vision Encoders by Enrico Fini, Mustafa Shukor, Xiujun Li, Philipp Dufter, Michal Klein, David Haldimann, Sai Aitharaju, Victor Guilherme Turrisi da Costa, Louis Béthune, Zhe Gan, Alexander T Toshev, Marcin Eichner, Moin Nabi, Yinfei Yang, Joshua M. Susskind, Alaaeldin El-Nouby.
The abstract from the paper is the following:
We introduce a novel method for pre-training of large-scale vision encoders. Building on recent advancements in autoregressive pre-training of vision models, we extend this framework to a multimodal setting, i.e., images and text. In this paper, we present AIMV2, a family of generalist vision encoders characterized by a straightforward pre-training process, scalability, and remarkable performance across a range of downstream tasks. This is achieved by pairing the vision encoder with a multimodal decoder that autoregressively generates raw image patches and text tokens. Our encoders excel not only in multimodal evaluations but also in vision benchmarks such as localization, grounding, and classification. Notably, our AIMV2-3B encoder achieves 89.5% accuracy on ImageNet-1k with a frozen trunk. Furthermore, AIMV2 consistently outperforms state-of-the-art contrastive models (e.g., CLIP, SigLIP) in multimodal image understanding across diverse settings.
- Add Aimv2 model by @yaswanth19 in #36625
PerceptionLM
The PerceptionLM model was proposed in PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding by Jang Hyun Cho et al. It's a fully open, reproducible model for transparent research in image and video understanding. PLM consists of
a vision encoder with a small scale (<8B parameters) LLM decoder.
- PerceptionLM by @shuminghu in #37878
Efficient LoFTR
The EfficientLoFTR m...